curve(dbinom(x, size = 1000, prob = 0.5), from = 450, to = 550, xlab = NA, ylab = NA)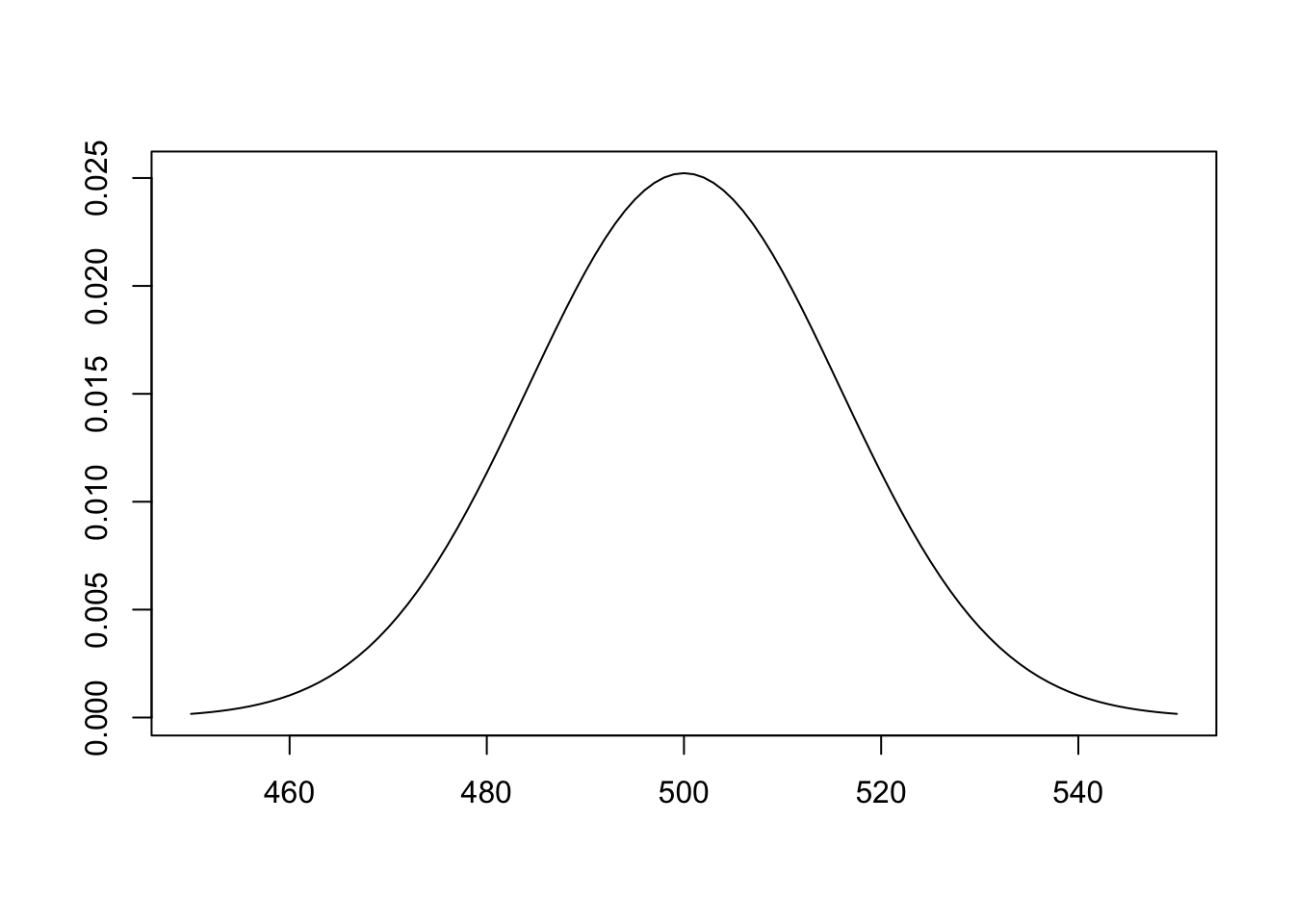
先日のゼミで、「1,000人が(ゆがみのない)コインを投げたら、表が出るのはだいたい500人と仮定していい」という話がありました。 表と裏それぞれの確率が\(1/2\)なので、なんとなく「半分になる」という感じで受け止めた人も多いと思います。 でも実際には、ぴったり500回になることはほとんどありません。 では、この「だいたい仮定していい」って、一体どういうことなんでしょうか?
言葉で説明する前に、実際に見てみましょう。 下に用意したのは、コインを1,000回投げた時に、表が出た比率の累積平均がどう変化するかのシミュレーションです。 とりあえず、[▶️ Start]ボタンを押してみてください。
#| '!! shinylive warning !!': |
#| shinylive does not work in self-contained HTML documents.
#| Please set `embed-resources: false` in your metadata.
#| standalone: true
#| viewerHeight: 600
library(shiny)
ui <- fluidPage(
actionButton("start", "▶️ Start"),
actionButton("stop", "⏹️ Stop"),
actionButton("reset", "🔄 Reset"),
br(),
h4(textOutput("status")),
br(),
plotOutput("plot", height = "500px"),
)
server <- function(input, output, session) {
rv <- reactiveValues(
x = numeric(0),
running = FALSE
)
step_fun <- function(i) {
if (i < 20) return(1)
if (i < 100) return(5)
return(20)
}
observeEvent(input$start, {
rv$running <- TRUE
})
observeEvent(input$stop, {
rv$running <- FALSE
})
observeEvent(input$reset, {
rv$x <- numeric(0)
rv$running <- FALSE
})
# 定期実行用のobserve
observe({
# Stopボタンが押されている、または初期状態の時は何もしない
if (!rv$running) return()
# 50ミリ秒ごとにこのブロックを再評価する
invalidateLater(50, session)
# isolateを使うことで、rv$xの更新による自己無限ループを防ぐ
isolate({
i <- length(rv$x)
if (i >= 1000) {
rv$running <- FALSE
return()
}
new <- rbinom(step_fun(i), 1, 0.5)
rv$x <- c(rv$x, new)
})
})
output$plot <- renderPlot({
if (length(rv$x) == 0) return(NULL)
y <- cumsum(rv$x) / seq_along(rv$x)
plot(
y,
type = "l",
ylim = c(0, 1),
col = "blue",
lwd = 2,
xlab = "Number of Trials",
ylab = "Cumulative Average",
cex.lab = 1.5, # 軸ラベル
cex.axis = 1.5 # 軸の数字
)
abline(h = 0.5, col = "red", lty = 2, lwd = 2)
})
output$status <- renderText({
n <- length(rv$x)
if (n == 0) {
return("試行回数: 0 | 表の回数: 0")
}
heads <- sum(rv$x)
sprintf("試行回数: %d | 表の回数: %d", n, heads)
})
}
shinyApp(ui, server)グラフの横軸は試行回数、縦軸は累積平均です。
最初(グラフの左端)の方をよく見てみると、試行結果を表す青い線が、「半々」を表す赤い破線から大きく外れていることがわかると思います。 シミュレーションのスタート当初は、「あれ、これ本当に半々になるの?」と不安になるくらいです。 しかしそのまましばらく見ていると、だんだんと青線が赤の波線に近づきます。
つまり、回数を増やすほど、割合が0.5に近づくということがわかります。 コインを投げた人数が50人の時は、そのうち表が出た人は25人だ、とはとても言えないですが、 人数が100人、500人、1,000人と増えていくと、まあ、だいたい半分と言ってもいいんじゃないかな、と思えてくると思います。
これがいわゆる大数の法則です。 ざっくり言うと、試行回数を増やすと、平均は理論値(ここでは0.5)に近づく、ということです。
シミュレーションを繰り返しやってみてください。 最初はめちゃくちゃぶれるグラフが徐々に安定してくる様子を観察することができます。 これはつまり「期待値とは長い目で見るもの」ということです。
コイン投げのように、結果が2通り(コイン投げの場合は表または裏)の試行を繰り返す場合の確率は、二項分布を用いて計算できます。 試行回数を\(n\)、1回の試行で表が出る確率を\(p\)とするとき、表が\(k\)回出る確率は、以下の式で表されます。
\[ P(X=k)=\binom{n}{k}p^k(1-p)^{n-k} \]
\(n=1000\)、\(p=0.5\)の時のグラフを描いてみましょう。
curve(dbinom(x, size = 1000, prob = 0.5), from = 450, to = 550, xlab = NA, ylab = NA)
表が出る回数は、500を中心とする山型の分布になっていて、中心付近の値が出やすく、端に行くほど急激に確率が小さくなります。 つまり「ぴったり500人」ではなくても、「500人から少しずれた範囲に収まる確率が非常に高い」ので、「だいたい500人と仮定できる」というわけです。
ちなみに、ちょうど500回になる確率は、先ほどの式に\(n=1000\)、\(p=0.5\)、\(k=500\)を代入することで計算できます。
\[ \begin{aligned} P(X = 500) &= \binom{1000}{500}(0.5)^{500}(0.5)^{500} \\ &= \binom{1000}{500}\frac{1}{2^{1000}} \end{aligned} \]
Rで計算すると、
choose(n = 1000, k = 500) / 2^1000[1] 0.02522502となり、およそ2.5%であることがわかります。 表がピッタリ500人になるのは、40回に1回程度しかないということですね。