library(tidyverse)
library(sf)
library(tmap)
library(tmaptools)国土数値情報 洪水浸水想定区域データとRを活用した災害リスクの可視化
ノートライセンス
本ドキュメントは、クリエイティブ・コモンズ・ライセンス表示4.0国際(CC BY 4.0)ライセンスのもとで提供されています(クリエイティブ・コモンズ・ライセンスについては、下記のサイトを参照してください)。 クリエイティブ・コモンズ・ライセンス表示4.0国際
本ドキュメントは下記の著作物をもとに改変して作成しています: 国土交通省 政策統括官付 地理空間情報課(協力:総合政策局 地域交通課)「国土数値情報 洪水浸水想定区域データとQGISを活用した災害リスクの可視化」(2025年4月) https://nlftp.mlit.go.jp/ksj/manual/QGIS_manual_02.htm (CC BY 4.0)
はじめに
近年、異常気象による水害のリスクが高まっており、自治体や住民にとって地域の災害リスクを正確に把握することがますます重要になっています。
国土交通省が提供している国土数値情報 洪水浸水想定区域データを活用することで、洪水時の被害を予測し、具体的な防災計画の策定が可能になります。
この記事では、主に自治体職員、地域防災に関心のある方、居住地域の災害リスクを知りたい方などを対象として、洪水浸水想定区域データをRで活用する方法について、以下の解析手順を紹介します。
- 洪水浸水危険度の可視化
- 洪水による浸水の範囲を示し、想定される浸水深ごとに色分けを行い浸水範囲内の危険度を可視化します。
- 各避難所における災害リスクの解析
- 避難所の地点をマップに示し、その位置における洪水浸水リスクを把握します。
注意
- この記事は、Rの基本操作ができることを前提として書かれています。
洪水浸水想定区域データとは
国土数値情報 洪水浸水想定区域データは、洪水時に浸水すると想定される範囲と浸水深を示したポリゴンデータであり、計画規模、想定最大規模、浸水継続時間、家屋倒壊等氾濫想定区域(氾濫流)、家屋倒壊等氾濫想定区域(河岸侵食)の5つのカテゴリに分類したデータを、地方整備局または都道府県ごとに整備して提供しています。
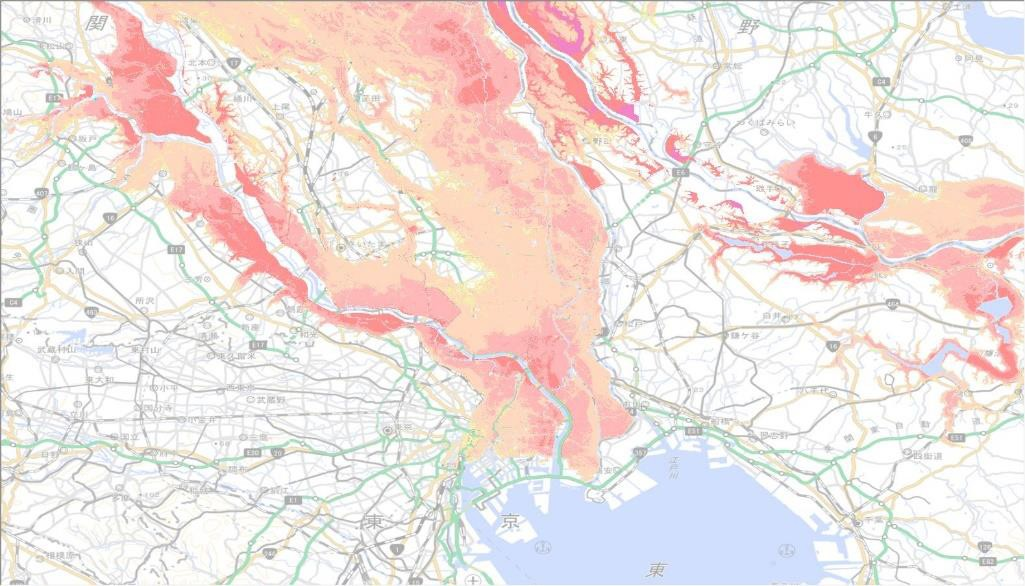
国土数値情報では、記事執筆時点で2012年度(平成24年度)と2019年度(令和元年度)から2024年度(令和6年度)までの整備データを公開しており、過去からの変遷も追うことができます。
洪水浸水想定区域データのダウンロードと追加
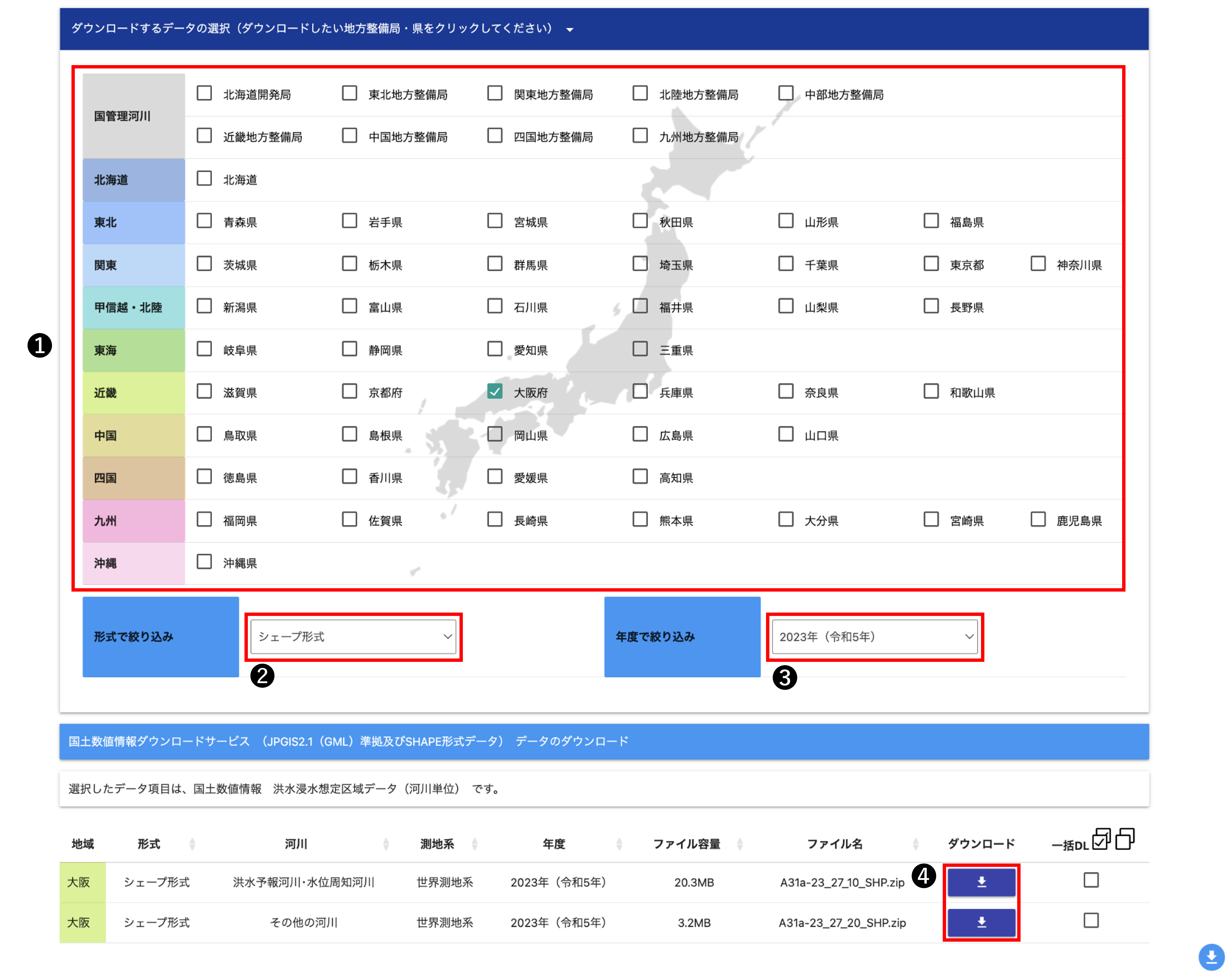
国土数値情報 洪水浸水想定区域データ(河川単位)のダウンロードページからデータのダウンロードを行います。 ページ下部に行くとダウンロード画面が表示されるので、ダウンロードしたいデータの絞り込みをします。 この記事では、2024年の大阪府のデータ(GeoJSON形式)をダウンロードします。
- ダウンロードしたい整備局もしくは都道府県にチェック
- ファイル形式を選択
- 整備年度を選択
- 選択した条件に合うデータセットが表示されるので、ダウンロードボタンをクリックしてデータをダウンロード
ダウンロードボタンをクリックすると、画面上に、「国土数値情報ダウンロードサイト ユーザーアンケート」が表示されるので、必要に応じて回答をお願いします。 回答を完了するか[スキップする]をクリックすることで、データのダウンロードが開始されます。
ダウンロードしたデータはZIP形式で圧縮されているため、解凍しましょう。 解凍すると「計画規模」、「想定最大規模」、「浸水継続時間」、「家屋倒壊等氾濫想定区域(氾濫流)」「家屋倒壊等氾濫想定区域(河岸侵食)」の5つのカテゴリごとにフォルダ分けされており、各フォルダの中に河川ごとに分かれたデータが格納されています。
以下では「想定最大規模」のデータを使いますので、「想定最大規模」フォルダ内のすべての.geojsonファイルをdataフォルダに移しておきます。
はじめに、使用するライブラリをロードしておきます。
ノート
以降では、ワーキングディレクトリに「data」という名前のデータフォルダがあり、使用するデータファイルはすべてdataフォルダに入っているものとします。
それでは、Rでデータを読み込みます。 以下のコードでは、dataフォルダにあるファイル名が「A31a」で始まるすべてのファイルを、sf::read_sf関数を使って読み込んでいます。
flood <-
list.files("data", "^A31a", full.names = TRUE) |>
map_df(read_sf) 読み込んだデータを地図にしてみましょう。
gsi_tile <- "https://cyberjapandata.gsi.go.jp/xyz/pale/{z}/{x}/{y}.png"
ksj_gsi_credit <- "国土数値情報および地理院タイルを加工して作成"
tm_shape(flood) +
tm_polygons(col = NULL, fill = "A31a_202") +
tm_layout(text.fontfamily = "BIZ UDPGothic") +
tm_credits(ksj_gsi_credit) +
tm_basemap(gsi_tile)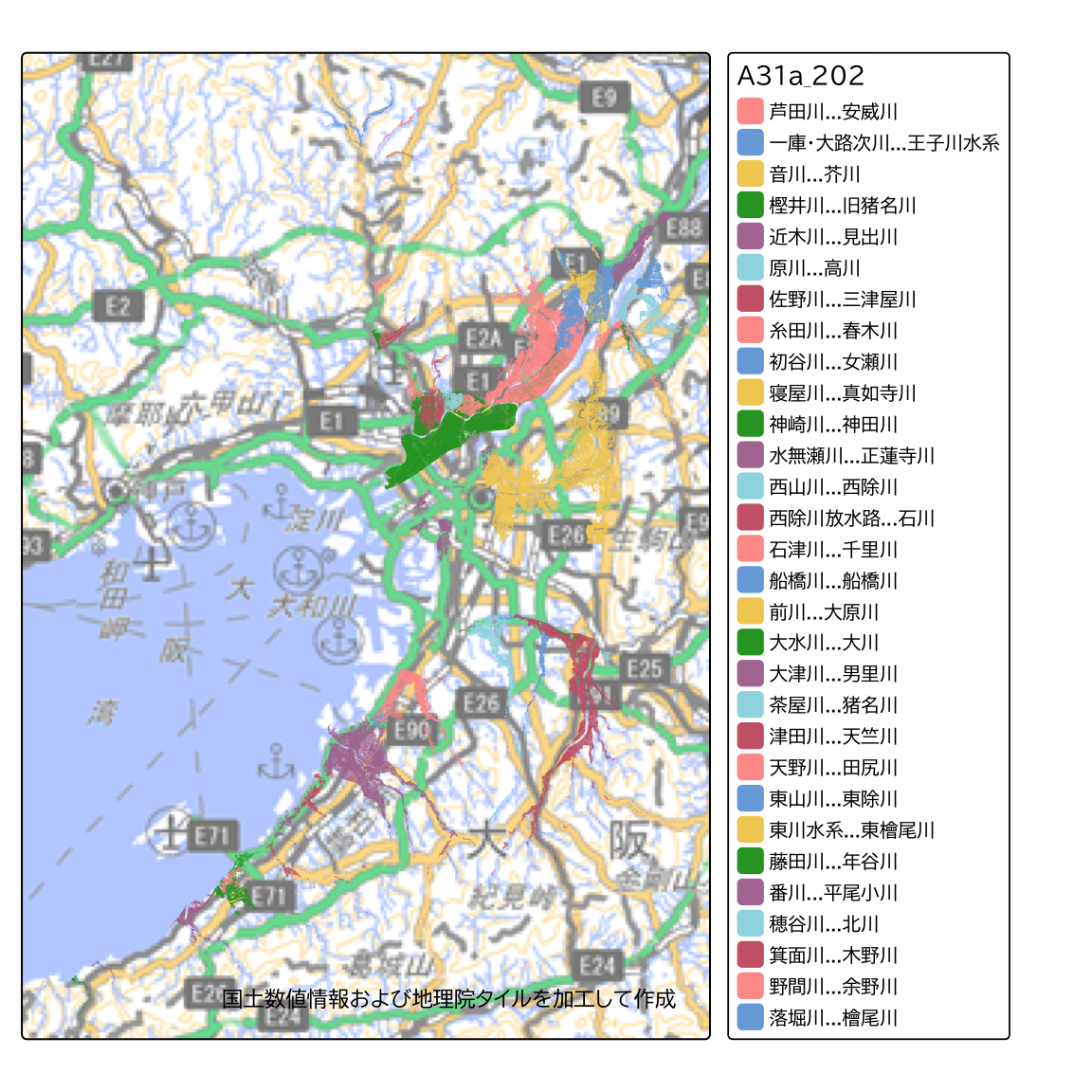
属性テーブルの確認
dplyr::glimpse関数を使って、属性データを確認しましょう。
glimpse(flood)Rows: 157,202
Columns: 6
$ A31a_201 <chr> "2700010001", "2700010001", "2700010001", "2700010001", "2700…
$ A31a_202 <chr> "東川水系", "東川水系", "東川水系", "東川水系", "東川水系", "東川水系", "東川水系", "東川水系…
$ A31a_203 <chr> "27", "27", "27", "27", "27", "27", "27", "27", "27", "27", "…
$ A31a_204 <chr> "大阪府", "大阪府", "大阪府", "大阪府", "大阪府", "大阪府", "大阪府", "大阪府", "大阪府"…
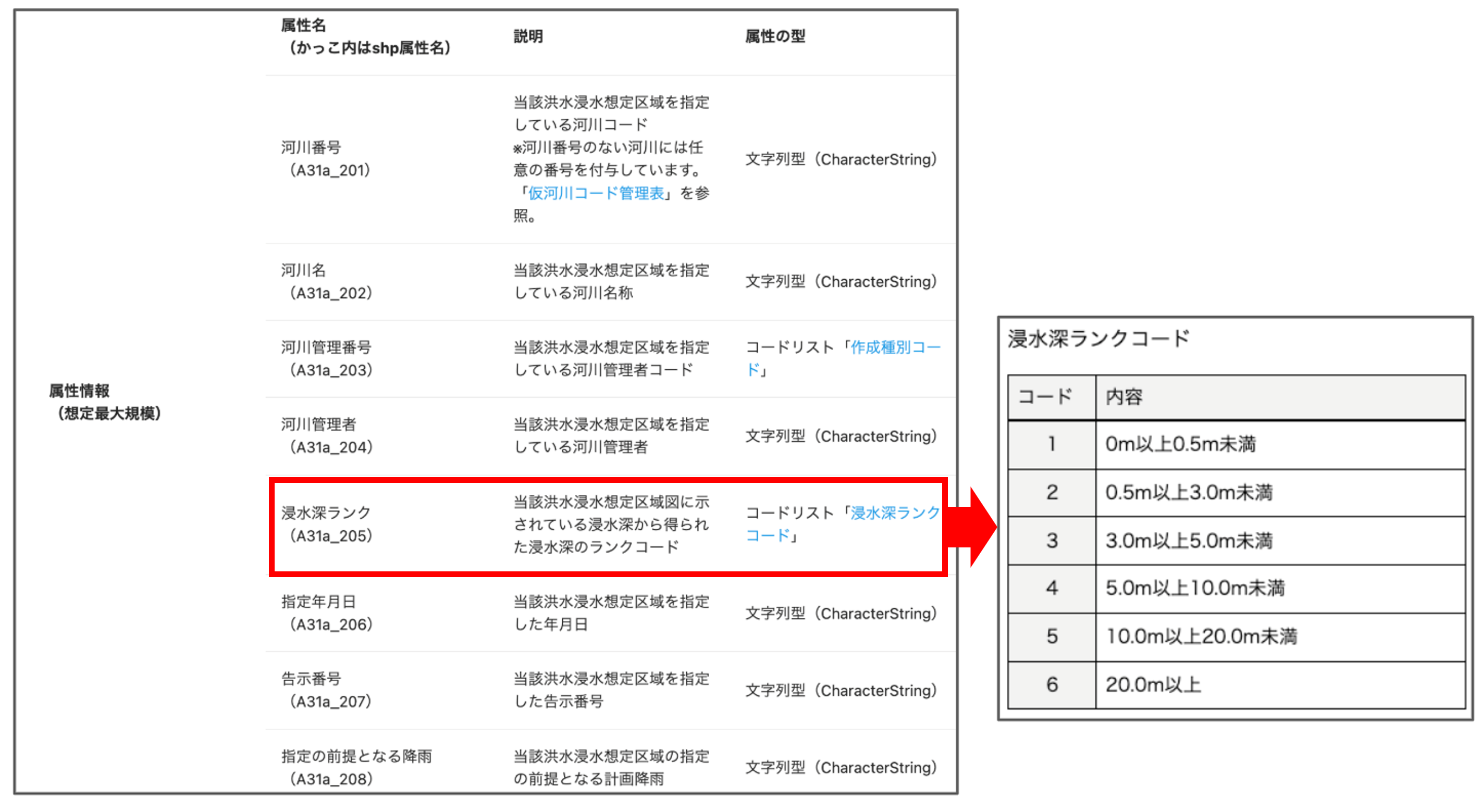
$ A31a_205 <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ geometry <POLYGON [°]> POLYGON ((135.1352 34.305, ..., POLYGON ((135.1351 34…洪水浸水想定区域データの属性には、河川名や河川管理者、浸水深ランクなどの情報が含まれています。
属性のカラム名や属性の説明については洪水浸水想定区域データのダウンロードページで確認することができます。 たとえば、想定最大規模データの場合「A31a_205」は浸水深ランクを示しており、1~6の値が入力されていることがわかります。
解析処理を始める前の補足(ジオメトリの修復)
この後のステップで紹介する「空間結合」などの処理を実行する際に、エラーが表示されて処理が実行できない場合は、データの幾何構造(ジオメトリ)に不具合がある可能性があります。
そのようなエラーが発生した場合は、「ジオメトリの修復」を実行しましょう。
flood <- st_make_valid(flood)洪水浸水深の可視化
浸水深ランクごとに色分けをする
洪水浸水深の配色については、住民のみならず旅行者や通勤・通学者がどこにいても水害リスクを認識し、避難行動を検討できるようにするために原則として統一する必要があり、ISO 等の基準や色覚障がいのある方への配慮、他の防災情報の危険度表示との整合性等を踏まえ、以下の配色を標準としています(洪水浸水想定区域図作成マニュアル)。

この配色に合わせて洪水浸水想定データを色分けするためのカラーパレットを作成します。
pal <- c(
rgb(247, 245, 169, maxColorValue = 255),
rgb(255, 216, 192, maxColorValue = 255),
rgb(255, 183, 183, maxColorValue = 255),
rgb(255, 183, 183, maxColorValue = 255),
rgb(255, 145, 145, maxColorValue = 255),
rgb(242, 133, 201, maxColorValue = 255),
rgb(220, 122, 220, maxColorValue = 255)
)このカラーパレットを使って、次のような地図を描画できます。
bbox <- st_bbox(
c(xmin = 135.48, xmax = 135.65, ymin = 34.71, ymax = 34.85),
crs = st_crs(6668)
)
tm_shape(bbox = bbox) +
tm_shape(flood) +
tm_polygons(
col = NULL,
fill = "A31a_205",
fill.scale = tm_scale_categorical(values = pal),
fill.legend = tm_legend(title = "想定最大\n浸水深ランク", reverse = TRUE)
) +
tm_layout(text.fontfamily = "BIZ UDPGothic") +
tm_credits(ksj_gsi_credit) +
tm_basemap(gsi_tile)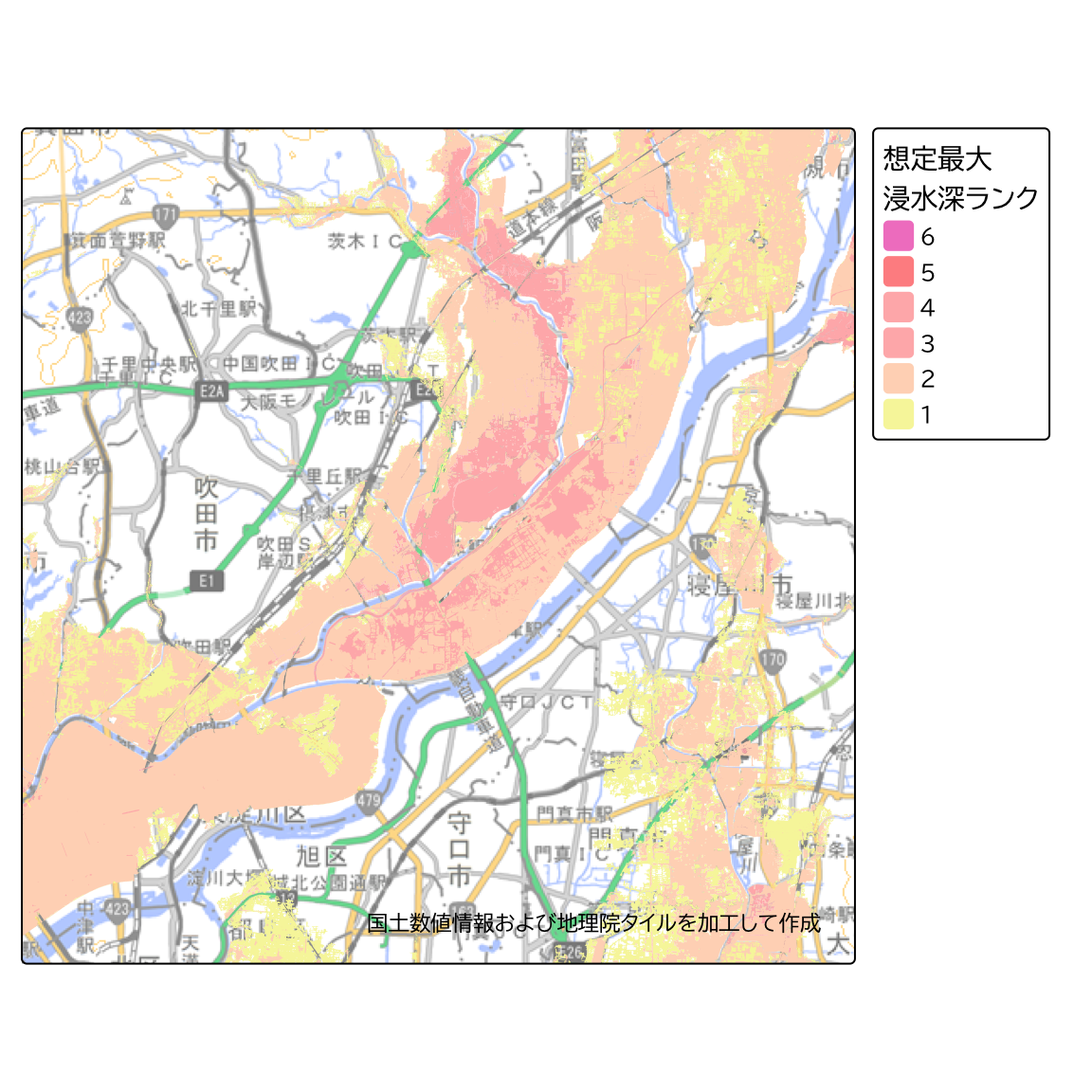
避難所ごとの浸水深を調べる
続いて、避難所ごとの浸水深を調べてみましょう。
今回は避難所のデータとして、国土地理院より公開されている「指定緊急避難所・指定避難所データ」を活用します。
ダウンロードページにアクセスすると、日本全国の「指定緊急避難場所」および「指定避難所」のデータを、都道府県・市町村別にダウンロードすることができるので、分析対象の地域の指定避難所データをダウンロードしましょう。
データはCSVファイルとGeoJSONファイルで取得することができます。 今回は「指定避難所」のGeoJSONファイルを利用しますので、ZIPファイルを解凍してGeoJSONファイルをdataフォルダに移してください。
「指定避難所」のデータをRに読み込みます。 データのCRSが「WGS 84」になっているので、「JGD2011(EPSG:6668)」に変換しておきます。
shelter <- read_sf("data/27000_1.geojson") |>
st_transform(6668)先ほどの地図に、「指定避難所」のデータを重ねてみます。
ksj_gsi_credit2 <- "国土数値情報、地理院タイルおよび指定避難所データ(国土地理院)を加工して作成"
tm_shape(bbox = bbox) +
tm_shape(flood) +
tm_polygons(
col = NULL,
fill = "A31a_205",
fill.scale = tm_scale_categorical(values = pal),
fill.legend = tm_legend(title = "想定最大\n浸水深ランク", reverse = TRUE)
) +
tm_shape(shelter) + tm_dots() +
tm_layout(text.fontfamily = "BIZ UDPGothic") +
tm_credits(ksj_gsi_credit2) +
tm_basemap(gsi_tile)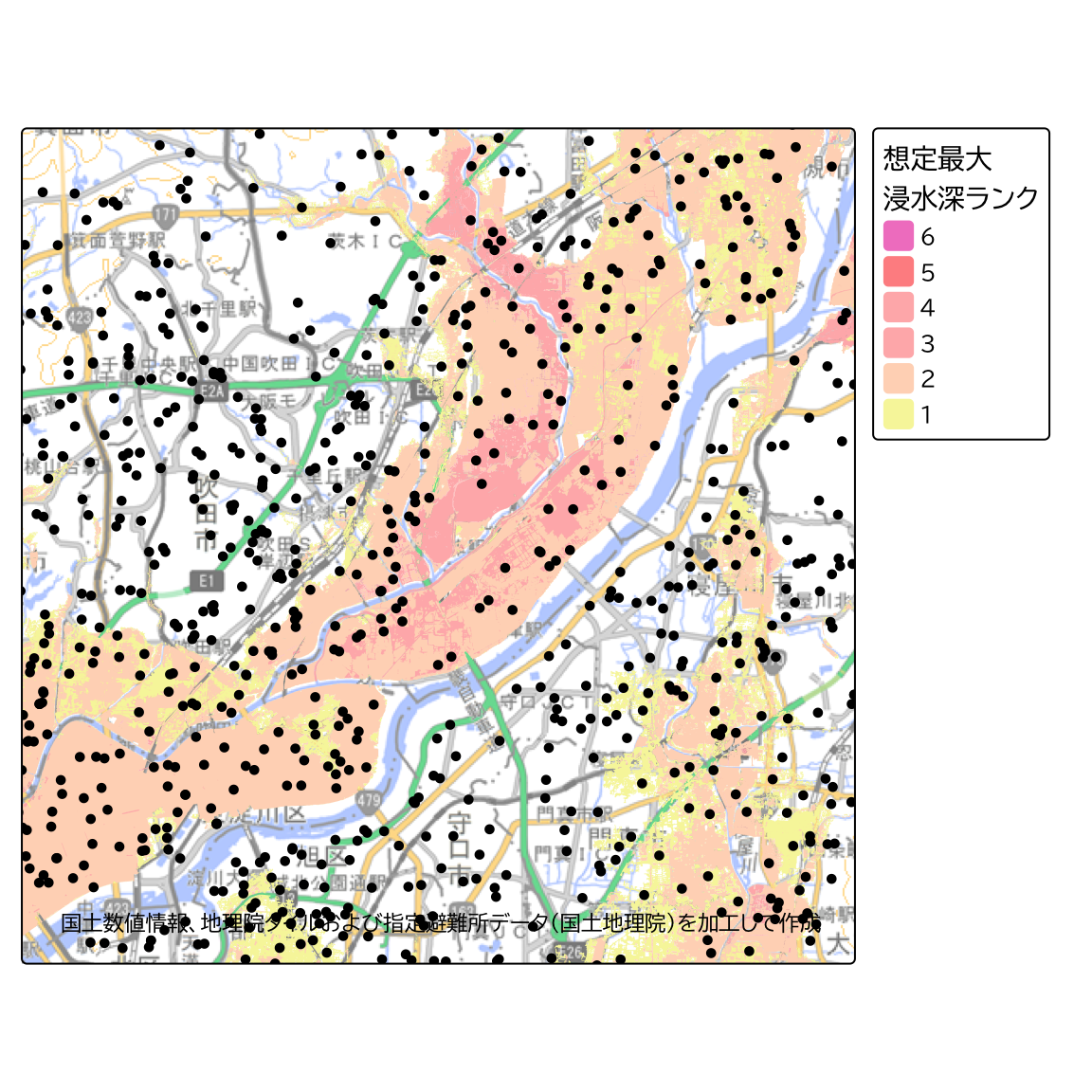
次に、避難所の地点の浸水ランクを調べるには、「属性の空間結合」を行います。 属性の空間結合は、重なり合うレイヤが存在する場合に、一方の属性をもう一方のデータの属性に付与する処理です。
属性の空間結合は、Rではsf::st_join関数で実行することができます。
shelter_rank <- st_join(shelter, flood)空間結合したポイントデータの属性を確認すると、元の避難所のポイントデータが持っていた属性に加えて、洪水浸水想定区域ポリゴンが持っていた属性が追加されていることが確認できます。
glimpse(shelter_rank)Rows: 3,159
Columns: 14
$ NO <chr> "1", "2", "3", "4", "5", "6", "7", "8…
$ 共通ID <chr> "E2721100001111", "E2721100002111", "…
$ `施設・場所名` <chr> "白川公民館", "東小学校", "安威小学校", "市民総合センター(ク…
$ 住所 <chr> "大阪府茨木市鮎川1-8-17", "大阪府茨木市鮎川2-5-23", "…
$ 指定緊急避難場所との住所同一 <chr> "1", "1", "1", "1", "1", "1", "1", "1…
$ その他市町村長が必要と認める事項 <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
$ 受入対象者 <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
$ 備考 <chr> "", "", "", "", "", "", "", "", "", "…
$ geometry <POINT [°]> POINT (135.5935 34.81649), POIN…
$ A31a_201 <chr> "8606040048", "8606040048", NA, "8606…
$ A31a_202 <chr> "安威川", "安威川", NA, "安威川", "安威川", NA, "…
$ A31a_203 <chr> "27", "27", NA, "27", "27", NA, "27",…
$ A31a_204 <chr> "大阪府", "大阪府", NA, "大阪府", "大阪府", NA, "…
$ A31a_205 <int> 2, 3, NA, 2, 2, NA, 2, 2, 2, 3, 3, 2,…また、洪水浸水想定データのレイヤと同様に、「A31a_205」列に浸水ランクの値が入力されています。 値が「NA」となっている避難所は、属性を結合する相手が見つからなかった(避難所が浸水想定区域ポリゴンと交差していなかった)ことを意味しています。
それでは、浸水想定区域ポリゴンを色分けした時と同様の手順で、ポイントデータを色分けしてみましょう。
high_risk_area <-
st_bbox(c(ymin = 34.77, xmin = 135.555, ymax = 34.83, xmax = 135.61), crs = st_crs(6668)) |>
st_as_sfc() |> st_as_sf()
tm_shape(bbox = bbox) +
tm_shape(shelter_rank) +
tm_dots(
fill = "A31a_205",
fill.scale = tm_scale_categorical(values = pal),
fill.legend = tm_legend(title = "想定最大\n浸水深ランク", reverse = TRUE)
) +
tm_shape(high_risk_area) +
tm_polygons(col = "red", fill = NULL, lwd = 2) +
tm_layout(text.fontfamily = "BIZ UDPGothic") +
tm_credits(ksj_gsi_credit2) +
tm_basemap(gsi_tile)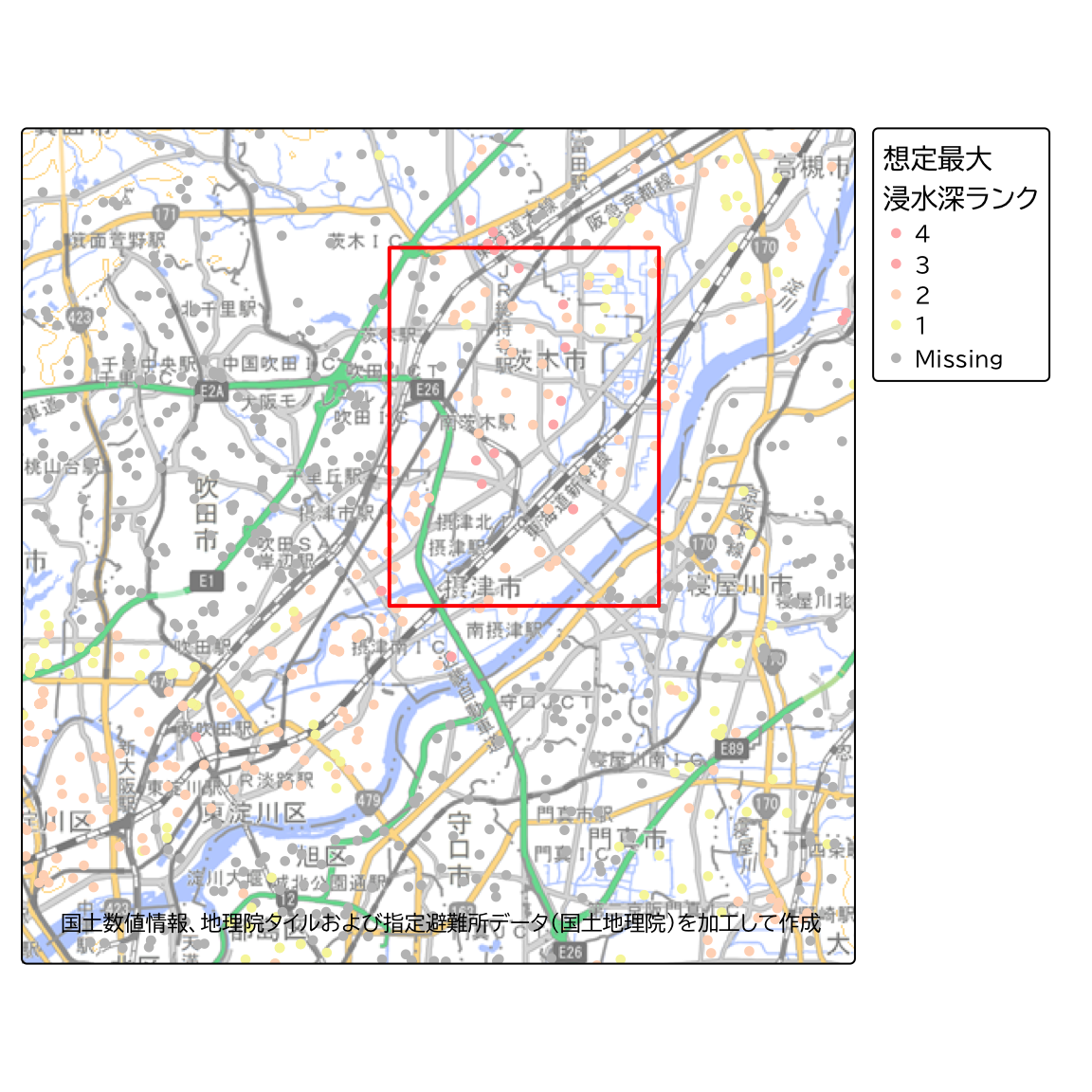
淀川右岸側の摂津市付近(図内赤枠の範囲)ではランク4に該当する避難所が多く、浸水深ランクが高いエリアであることがわかります。
最後に、浸水ランクごとの避難所の件数を集計してみます。
table(shelter_rank$A31a_205)
1 2 3 4
323 569 49 6 table関数を使うことで、浸水深ランクごとに避難所が何件あるのか把握することができます。
今回分析対象としている大阪府のデータでは、「浸水ランク5(10m以上20m未満)」や「浸水ランク6(20m以上)」の地点は存在しませんが、「浸水ランク4(5m以上10m未満)」に該当する避難所が6件存在することが確認できます。
将来推計人口データを活用した洪水浸水想定区域内の人口分析
国土数値情報 メッシュ別将来推計人口データを活用することで、洪水浸水想定区域内の人口を分析することも可能です。
全ての領域を対象とすると処理に時間がかかるので、今回は例として、大和川沿いの浸水ランクが4以上のポリゴンを抽出して、人口分析をしてみます。 対象範囲は以下のとおりです。
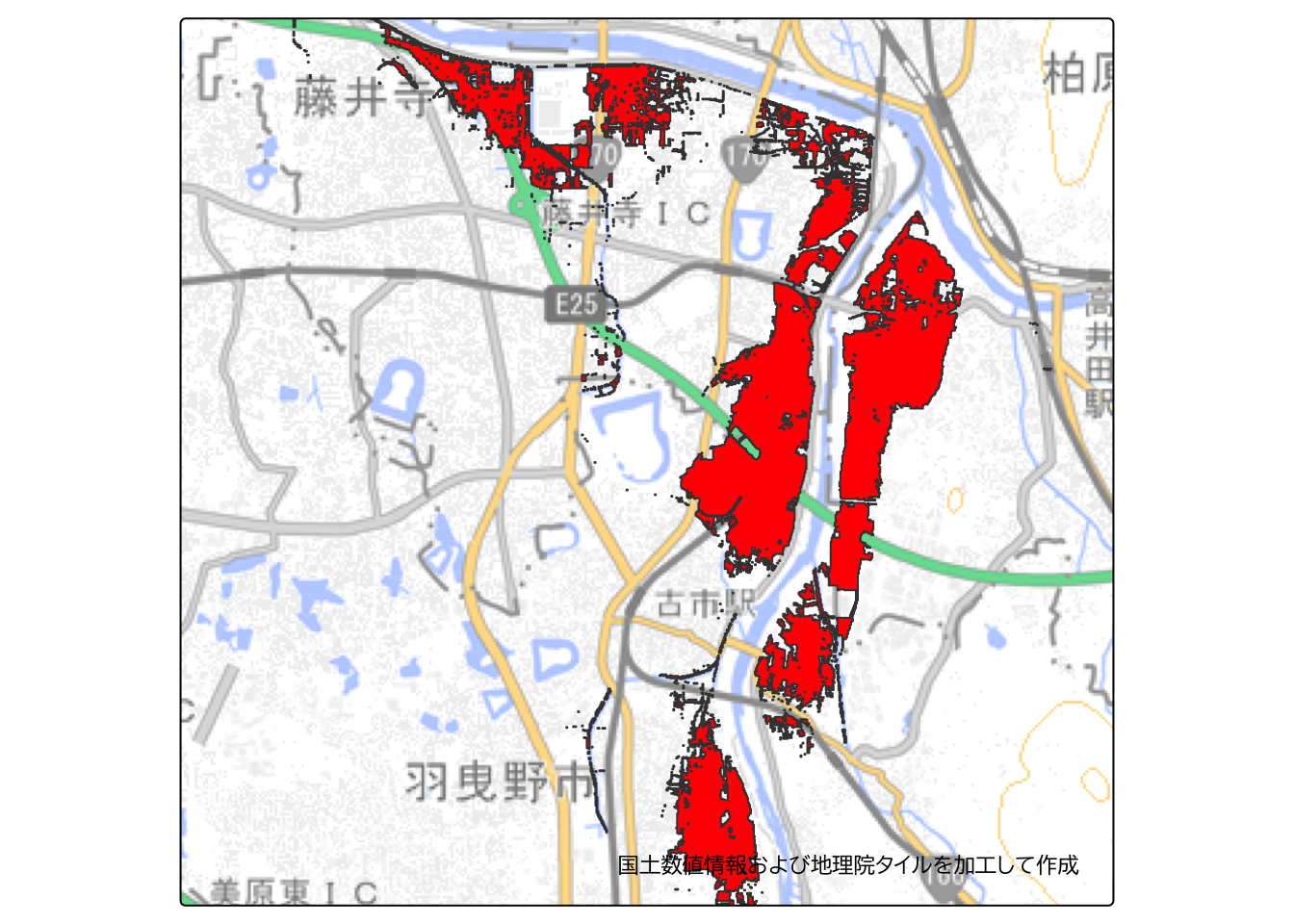
国土数値情報から、大阪市の250 mメッシュ別将来推計人口データ(R6国政局推計)データをRに読み込んで、上記の範囲で2020年(PTN_2020)の人口データを基に面積按分を行った結果を以下に示します。
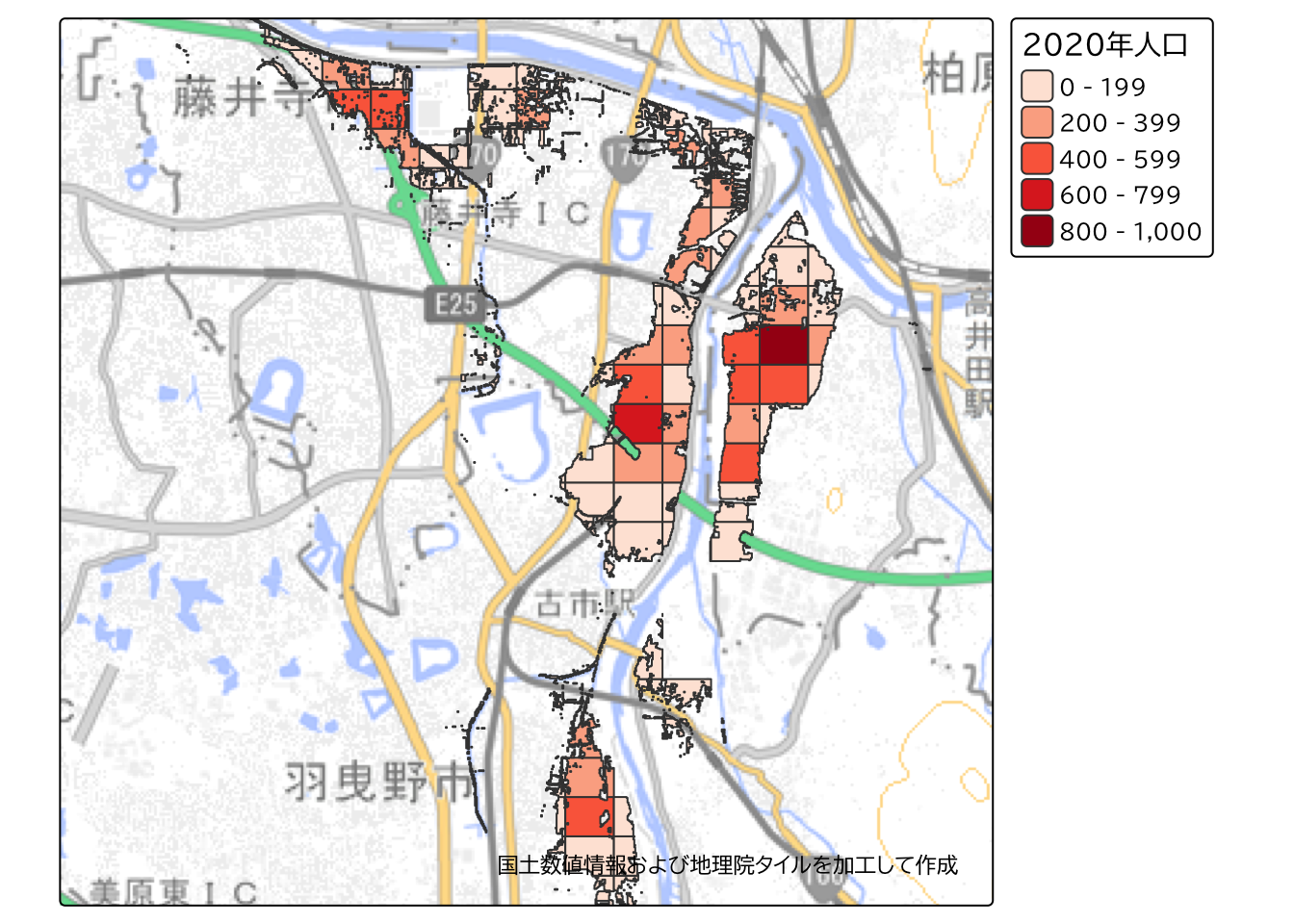
分析の結果、洪水浸水ランクが4以上のエリアには多数の人口が居住していることが確認されました。
面積按分による人口分析の方法については、「国土数値情報とRを活用した交通空白地の抽出と人口分析」の記事で紹介していますので、ぜひご参照ください。
おわりに
この記事では、Rを活用した国土数値情報の洪水浸水想定区域データの利用方法について、具体的な事例を紹介しました。 浸水深ごとの色分け表示や避難所ごとの浸水深ランクの解析を行うことで、より効果的な防災対策を進めることができます。
このようなデータを活用することで、住民一人ひとりが災害リスクを把握し、防災意識を高めることが可能となります。 Rを用いた地域の災害リスクの可視化に、ぜひ取り組んでみてください。
ノート使用したパッケージについて
この記事の執筆に使用したパッケージとそのバージョンは以下の通りです。
A large number of files (1137 in total) have been discovered.
It may take renv a long time to scan these files for dependencies.
Consider using .renvignore to ignore irrelevant files.
See `?renv::dependencies` for more information.
Set `options(renv.config.dependencies.limit = Inf)` to disable this warning.| package | loadedversion | source |
|---|---|---|
| sf | 1.1-1 | CRAN (R 4.6.0) |
| tidyverse | 2.0.0 | CRAN (R 4.6.0) |
| tmap | 4.3 | CRAN (R 4.6.0) |
| tmaptools | 3.3 | CRAN (R 4.6.0) |
| units | 1.0-1 | CRAN (R 4.6.0) |