library(tidyverse)
library(sf)
library(tmap)
library(tmaptools)国土数値情報 地価公示データとRを活用した都市の地価分析
ノートライセンス
本ドキュメントは、クリエイティブ・コモンズ・ライセンス表示4.0国際(CC BY 4.0)ライセンスのもとで提供されています。
クリエイティブ・コモンズ・ライセンスについては、下記のサイトを参照してください。 クリエイティブ・コモンズ・ライセンス表示4.0国際
本ドキュメントは下記の著作物をもとに改変して作成しています:
国土交通省政策統括官付地理空間情報課「国土数値情報 地価公示データとQGISを活用した都市の地価分析」(2025年4月)
https://nlftp.mlit.go.jp/ksj/manual/QGIS_manual_03.htm (CC BY 4.0)
はじめに
この記事では、国土数値情報で公開されている地価公示データのRでの活用方法について解説します。 主に自治体職員、不動産業者、都市計画コンサルタントを対象として、以下の2つの解析方法を紹介します。
- 地価の変動率の可視化
- 地価の変動率を地図上で示すことで、上昇・横ばい・下落地点を直感的に把握できるようにします。
- 地価公示の用途ごとにフィルタリングを行い、用途ごとに変動率の変化を把握できるようにします。
- 駅から500メートル圏内の地価公示価格の集計
- 駅データを活用して、各駅から半径500メートル圏内にある地価公示地点の価格を集計することで、駅ごとの地価動向を把握できるようにします。
これらの手法により、地価の動向を視覚的に把握し、効果的な不動産分析や都市計画の検討に活用できます。
注意
- この記事は、Rの基本操作ができることを前提として書かれています。
地価公示とは
地価公示とは、地価公示法に基づき、都市計画区域等における標準的な地点の毎年1月1日時点の1㎡あたりの正常な価格を国土交通省土地鑑定委員会が判定・公示するものです。 公示価格は、一般の土地の取引価格に対して指標を与えるとともに、公共事業用地の取得価格の算定等の規準とされています。
また、国土交通省が公開している「不動産情報ライブラリ」では、地図で地価公示の地点の価格などを確認することが可能です。
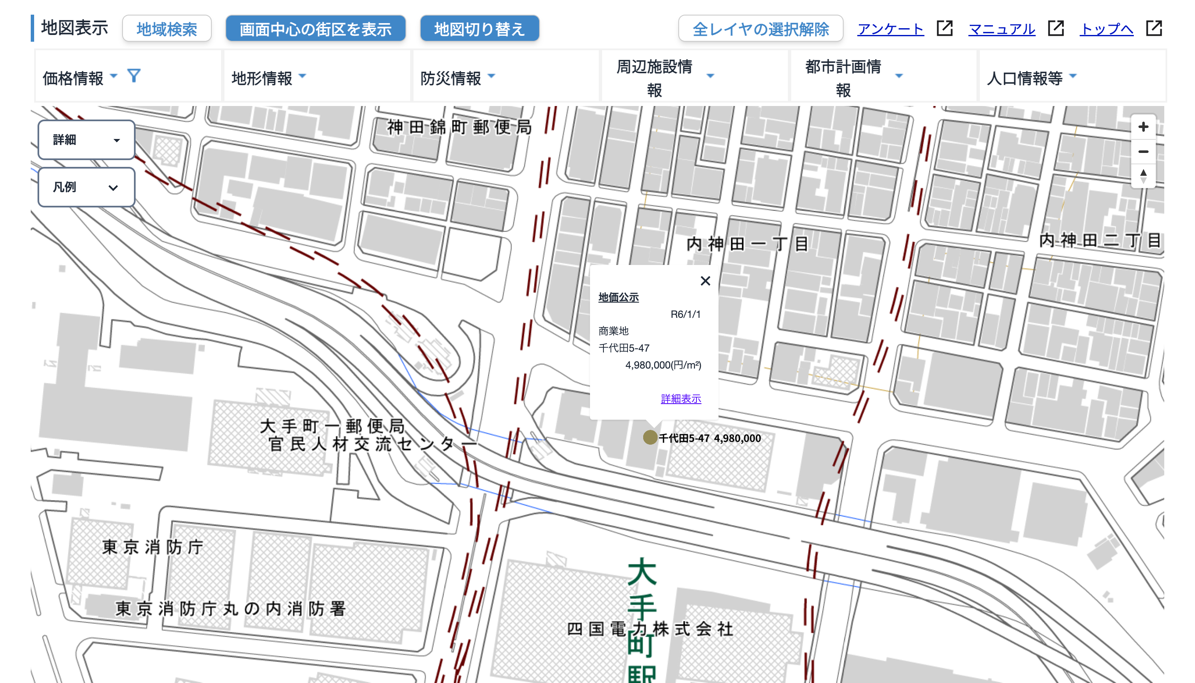
国土数値情報では、1983年(昭和58年)以降の地価公示データを公開しており、地価や利用状況などの情報が属性データとして整備されています。 2025年3月には、2025年1月1日時点の価格を反映した最新の地価公示データが公開されました。
地価公示データのダウンロードと表示
それでは、国土数値情報から地価公示データをダウンロードしましょう。
国土数値情報の地価公示データのダウンロードページにアクセスします。 次に、ページの下部へスクロールをすると、ダウンロード対象の地域を選択できる画面が表示されるので、目的のエリアの行の一番右にある[ダウンロード]ボタンをクリックしましょう。 なお、本記事では、東京都のデータをダウンロードして以降の説明を行います。
画面上に、「国土数値情報ダウンロードサイト ユーザーアンケート」が表示されるので、必要に応じて回答を行いましょう。 回答を完了するか[スキップする]をクリックすることで、データのダウンロードが開始されます。
データのダウンロードが完了したら、ZIPファイルを解凍してできたファイルの中から「L01-25_13.geojson」をデータフォルダに追加しましょう。
ノート
以降では、ワーキングディレクトリに「data」という名称のデータフォルダがあるものとします。
ダウンロードしたデータを、Rに読み込みましょう。 ここでは「land_price」という変数に代入しています(便宜上、filter関数を使って、島嶼部のデータを含まないデータセットを作っています)。
land_price <- read_sf("data/L01-25_13.geojson") |>
filter(!L01_024 %in% c("東京大島", "新島", "神津島", "東京三宅", "八丈", "小笠原"))地図に表示してみましょう。
gsi_tile <- "https://cyberjapandata.gsi.go.jp/xyz/pale/{z}/{x}/{y}.png"
ksj_gsi_credit <- "国土数値情報および地理院タイルを加工して作成"
tm_shape(land_price) + tm_dots() +
tm_layout(text.fontfamily = "BIZ UDPGothic") +
tm_basemap(gsi_tile) +
tm_credits(ksj_gsi_credit) 
続いて、地価公示データの属性テーブルを確認します。
as_tibble(land_price)# A tibble: 2,542 × 147
L01_001 L01_002 L01_003 L01_004 L01_005 L01_006 L01_007 L01_008 L01_009
<chr> <chr> <chr> <chr> <chr> <chr> <int> <int> <dbl>
1 13101 000 001 13101 000 001 2025 3960000 10
2 13101 000 002 13101 000 002 2025 2530000 11.9
3 13101 000 003 13101 000 003 2025 4830000 10
4 13101 000 004 13101 000 004 2025 1970000 13.2
5 13101 000 005 13101 000 005 2025 3680000 10.2
6 13101 000 006 13101 000 006 2025 2270000 10.7
7 13101 000 007 13101 000 007 2025 3740000 10
8 13101 005 001 13101 005 001 2025 14600000 2.1
9 13101 005 002 13101 005 002 2025 37100000 0.8
10 13101 005 003 13101 005 003 2025 1760000 18.9
# ℹ 2,532 more rows
# ℹ 138 more variables: L01_010 <int>, L01_011 <chr>, L01_012 <chr>,
# L01_013 <chr>, L01_014 <chr>, L01_015 <chr>, L01_016 <chr>, L01_017 <chr>,
# L01_018 <chr>, L01_019 <chr>, L01_020 <chr>, L01_021 <chr>, L01_022 <chr>,
# L01_023 <chr>, L01_024 <chr>, L01_025 <chr>, L01_026 <chr>, L01_027 <int>,
# L01_028 <chr>, L01_029 <chr>, L01_030 <chr>, L01_031 <chr>, L01_032 <chr>,
# L01_033 <chr>, L01_034 <chr>, L01_035 <chr>, L01_036 <dbl>, …属性テーブルを確認すると、多数の列が存在していることがわかります。 また、それぞれの属性名が「L01_001」のような形式で記載されていることもわかります。
それぞれの属性が何を示しているか確認したい場合は、地価公示データのダウンロードページにある「地物情報」の欄を参照してください。
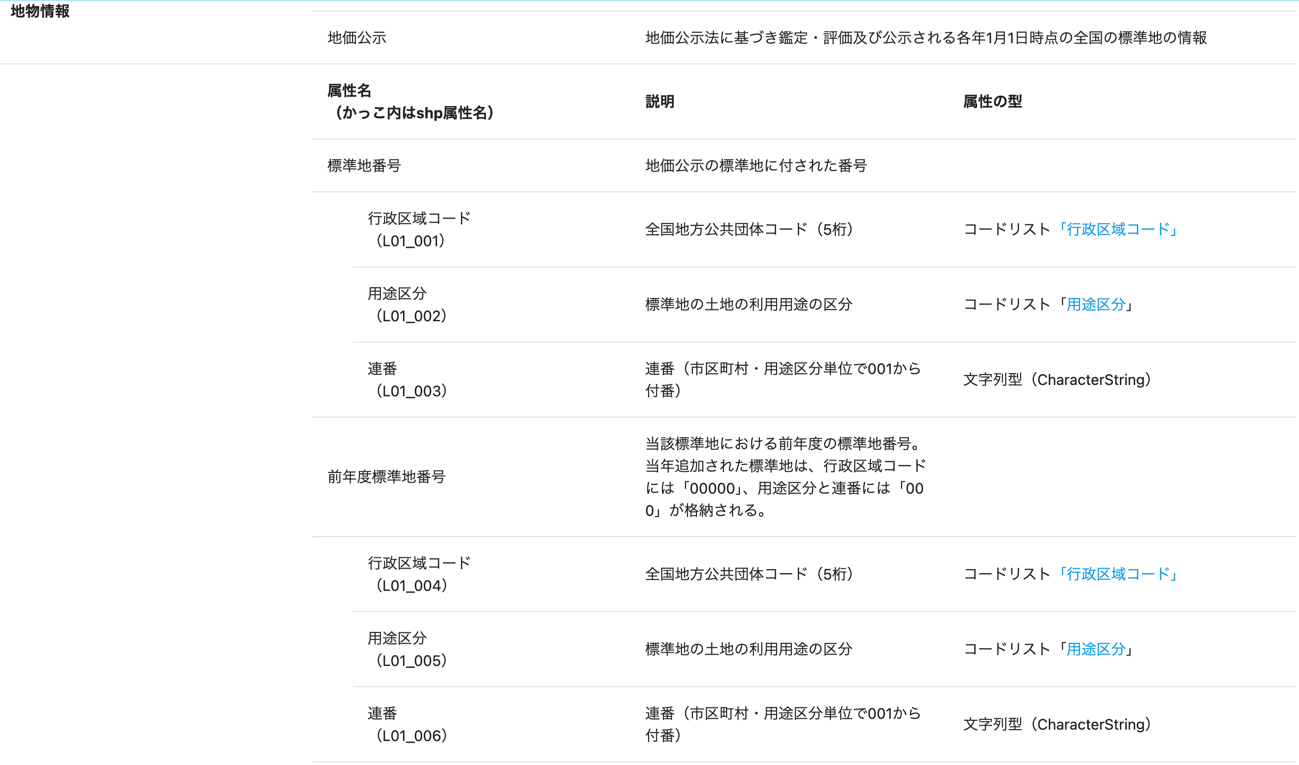
なお、この記事で主に使用する属性の説明については以下の通りです。
| 属性名 | 説明 |
|---|---|
| L01_002 用途区分 |
標準値の土地の利用用途の区分 000:住宅地、003:宅地見込地、005:商業地、009:工業地、013:林地 |
| L01_008 地価公示価格 |
標準地の当年の地価公示価格(単位は[円/㎡]) |
| L01_009 対前年変動率 |
継続する標準地について、前年の地価公示価格との対比から算出したもの(単位は[%]、小数点以下第2位を四捨五入) \[対前年変動率=\frac{当年価格-前年価格}{前年価格}\times 100\] |
地価公示データの変動率の可視化
変動率に応じたスタイル設定
次に、地価公示の「対前年変動率(L01_009)」を用いて、地価の上昇・横ばい・下落地点を視覚的に把握しやすいようにスケールを設定します。
range(land_price$L01_009)[1] -1.3 32.7今回のデータでは変動率が-1.3%から32.7%までの範囲になっています。 変動率は一般的に「下落」「横ばい(変動なし)」「上昇」という分類で表現することが多いため、この設定を実用的な区分として作成します。
ここでは、「下落」(-1.3%〜-0.001%)と「横ばい」(-0.001%〜0%)を作成し、「上昇」は5ポイント刻みで複数の分類を作成しています。
このデータでは地価上昇地点が多いため、上昇の分類を細かく設定していますが、データごとに変動傾向は異なります。 そのため、分析するデータの特徴に応じて分類を調整するとよいでしょう。
breaks <- c(-1.3, -0.01, 0, 5, 10, 15, 20, 25, 32.7)
fill_scale <- tm_scale_intervals(
n = 7, style = "fixed", midpoint = NA,
breaks = breaks,
values = "-matplotlib.spectral")
tm_shape(land_price) +
tm_dots(
fill = "L01_009",
fill.scale = fill_scale,
fill.legend = tm_legend(title = "対前年変動率")
) +
tm_layout(text.fontfamily = "BIZ UDPGothic") +
tm_credits(ksj_gsi_credit) +
tm_basemap(gsi_tile)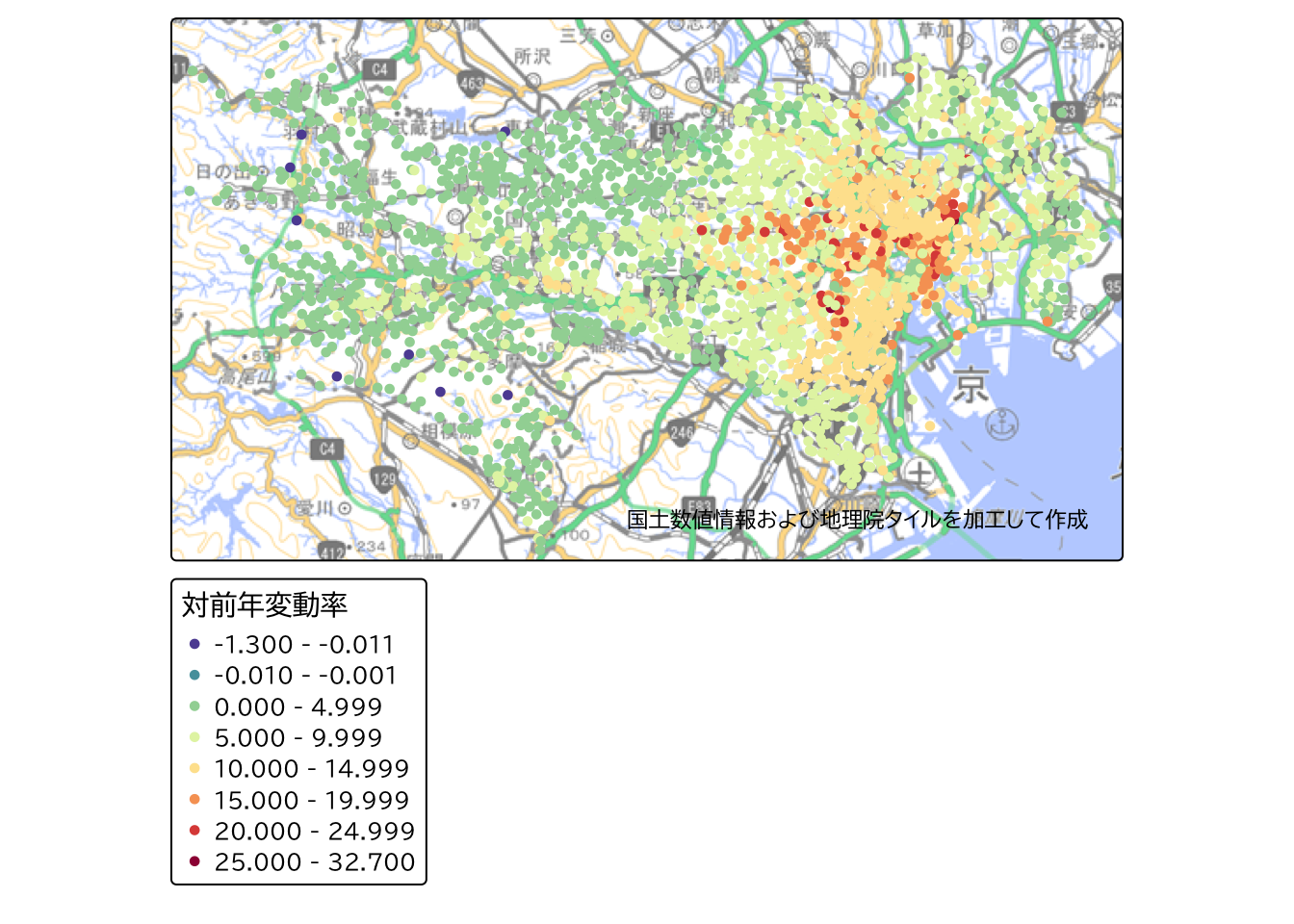
地域ごとの特徴を見ると、都心部では10%以上の上昇を示す地点が目立つことがわかります。 一方、郊外に向かうにつれて、上昇率が低くなっており、0〜10%程度の上昇にとどまる地点が多くなっていることがわかります。
このように、変動率を「連続値による定義」で階級区分することで、地域全体の地価の動向を視覚的に把握できます。
次に、各分類の地点数を確認してみましょう。
freq <- hist(land_price$L01_009, breaks = breaks, plot = FALSE)
freq$counts[1] 8 51 904 920 502 126 28 3cumsum(freq$counts) / sum(freq$counts) * 100[1] 0.3147128 2.3210071 37.8835563 74.0755311 93.8237608 98.7804878
[7] 99.8819827 100.0000000「下落」「横ばい」を合わせた比率がおよそ2.3%強であることがわかります。 数値からも、対象地点の97%以上で地価が上昇していることが確認でき、東京都では全域的に上昇傾向にあることが確認できます。
フィルタ機能で用途ごとに変動率の確認
地価公示では、土地を住宅地、商業地、工業地などの用途区分に分類しています。用途ごとに地価の変動パターンが異なるケースもあるので、それぞれの用途区分で変動率を確認することが有用です。
ここでは、フィルタ機能を使って、用途別の変動率を見ていきましょう。
ここでは、filter関数を使って、地価公示の「用途区分(L01_002)」が「商業地(005)」の地点のみを抽出します。
land_price |>
filter(L01_002 == "005") |>
tm_shape() +
tm_dots(
fill = "L01_009",
fill.scale = fill_scale,
fill.legend = tm_legend(title = "対前年変動率")
) +
tm_layout(text.fontfamily = "BIZ UDPGothic") +
tm_credits(ksj_gsi_credit) +
tm_basemap(gsi_tile)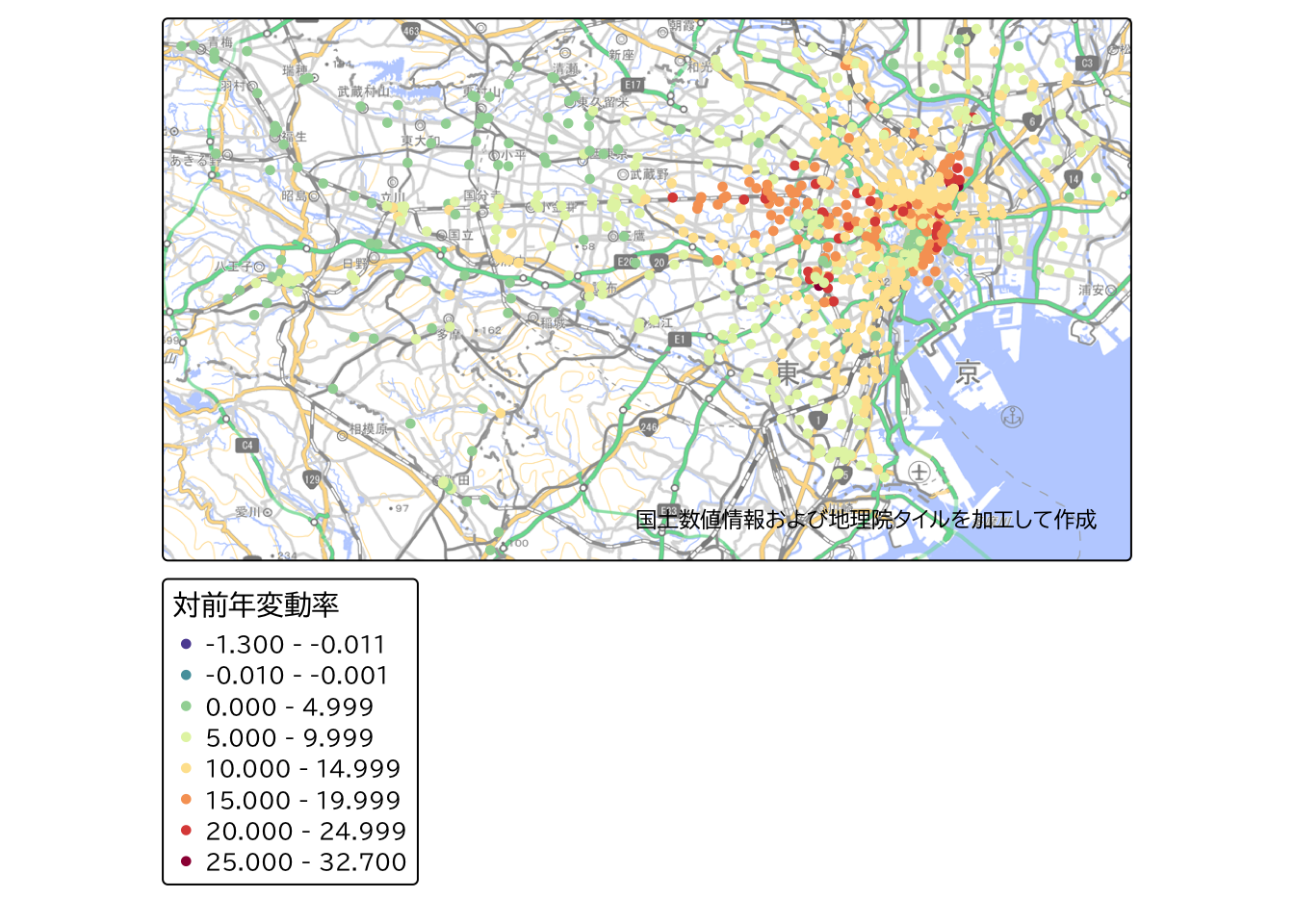
結果を確認してみると、商業地では浅草駅周辺で20%以上の顕著な地価上昇を示す地点が集中していることがわかります。
land_price |>
filter(L01_002 == "005") |>
tm_shape(bbox = bb(URLencode("東京駅"), width = 0.2, height = 0.1)) +
tm_dots(
fill = "L01_009",
fill.scale = fill_scale,
fill.legend = tm_legend(title = "対前年変動率")
) +
tm_layout(text.fontfamily = "BIZ UDPGothic") +
tm_credits(ksj_gsi_credit) +
tm_basemap(gsi_tile)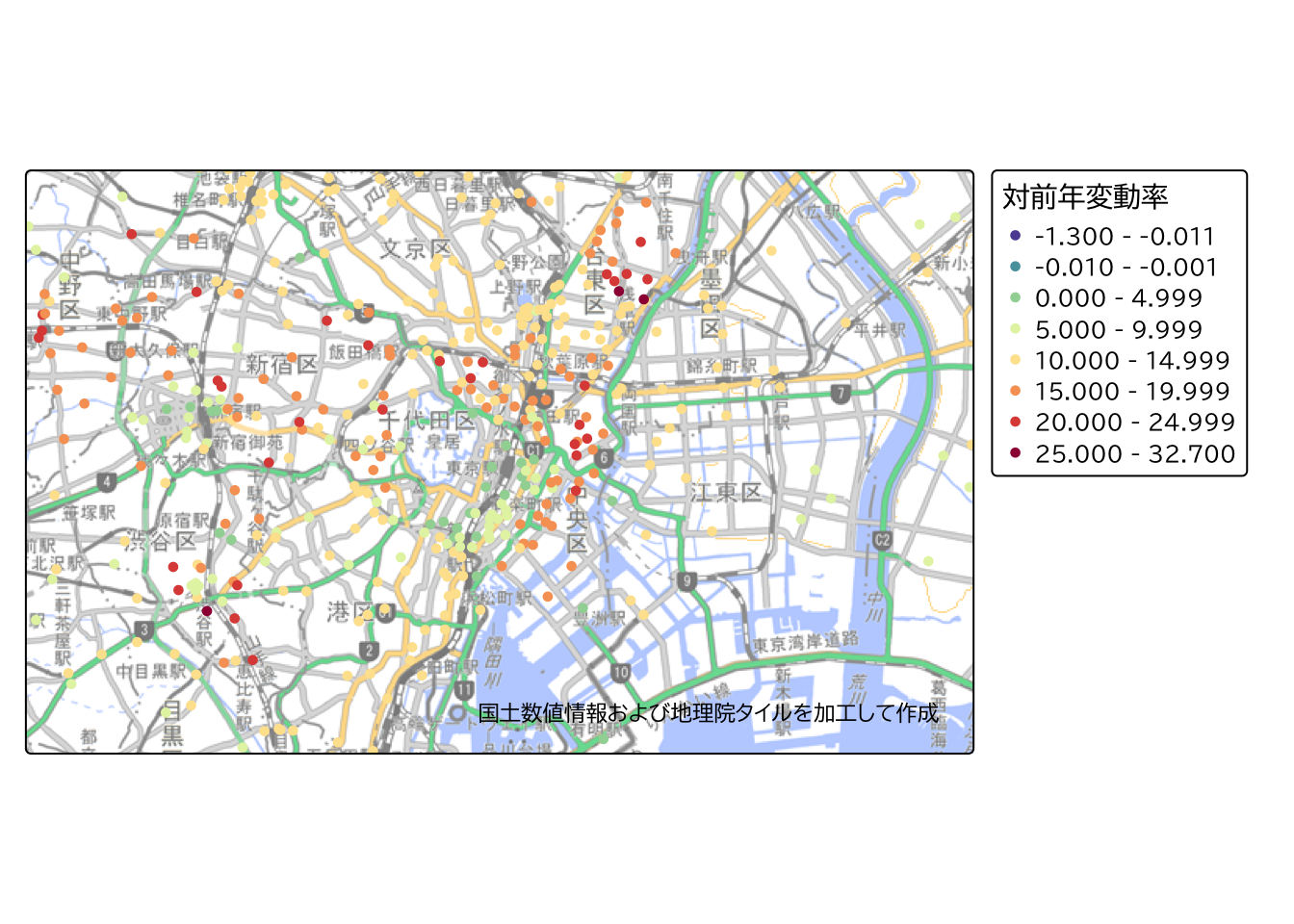
今度は、フィルタの設定を変更し、住宅地に絞って(L01_002 == "000")結果を確認してみます。 商業地と比較すると、顕著な地価上昇を示す地点が集中している地点は見受けられませんが、商業地の変動とは異なり、一部のエリアにおいて横ばいとなっている地点が点在していることがわかります。
land_price_housing <-
land_price |> filter(L01_002 == "000")
tm_shape(
land_price_housing,
bbox = bb(URLencode("市ケ谷"), width = 0.2, height = 0.1)
) +
tm_dots(
fill = "L01_009",
fill.scale = fill_scale,
fill.legend = tm_legend(title = "対前年変動率")
) +
tm_shape(land_price_housing, filter = land_price_housing$L01_009 < 0.001) +
tm_squares(fill = NULL, col = "red") +
tm_layout(text.fontfamily = "BIZ UDPGothic") +
tm_credits(ksj_gsi_credit) +
tm_basemap(gsi_tile)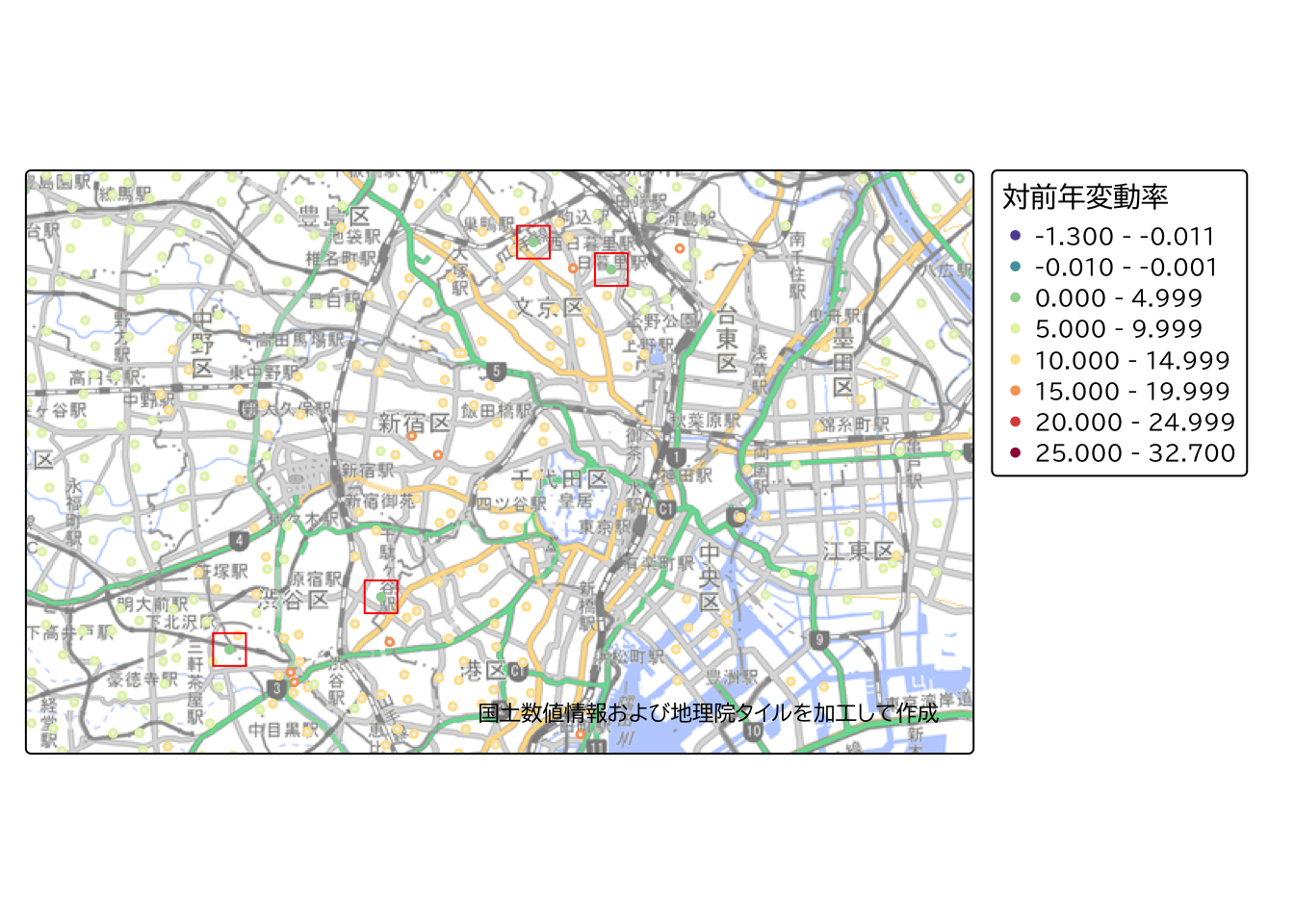
このようにフィルタ機能を活用することで、用途区分などの分類ごとに地価変動の特徴や傾向を個別に分析することができ、より詳細な地域特性の把握が可能となります。 地価は用途ごとに異なる変動パターンを示す傾向があるため、用途別の分析は地価動向を理解する上で重要な視点となるでしょう。
駅から500メートル圏内の地価の分析
次に、国土数値情報の駅データを活用して、より詳細な地価分析を行います。
具体的には、駅データを追加して各駅から半径500メートル圏内にある地価公示地点を特定します。 これらの価格データを集計することで、駅周辺の地価動向を把握できます。
駅データの読み込み
まずは、国土数値情報から鉄道データをダウンロードします。 ZIPファイルを解凍すると、「Shift-JIS」と「UTF-8」の2つのフォルダがありますので、「UTF-8」フォルダを開きます。 GeoJSONファイルが2つ格納されていますが、このうち「N02-24_Station.geojson」を使用しますので、これをワーキングディレクトリのデータフォルダに移動します。
station <- read_sf("data/N02-24_Station.geojson")
station |>
tm_shape() + tm_dots() +
tm_layout(text.fontfamily = "BIZ UDPGothic") +
tm_credits(ksj_gsi_credit) +
tm_basemap(gsi_tile)
鉄道データは全国規模で作成がされているため、対象路線を絞って集計を行います。 今回は路線名(N02_003)が「中央線」のみを抽出します。
station <- station |> filter(N02_003 == "中央線")
station |>
tm_shape() + tm_dots() + tm_basemap() +
tm_layout(text.fontfamily = "BIZ UDPGothic") +
tm_credits(ksj_gsi_credit) +
tm_basemap(gsi_tile)
注意
東京駅は中央線として属性が入力されているため、このまま処理すると東京駅が除外されてしまいます。 東京駅を含めたい場合は、filter関数の引数を、N02_003 == "中央線" | N02_005 == "東京"としましょう。
フィルタリングにより中央線の駅のみが表示されました。 中央線は東京都から愛知県まで延びる路線であるため、東京都外の駅も含まれています。
このまま処理を進めることもできますが、今回は東京都の地価公示データを使用しているため、他の都道府県のデータは不要です。 そこで、東京都のデータのみを抽出します。 行政区域のデータを使用して、東京都のポリゴンと重なる地物のみを抽出する方法もありますが、ここではより簡便な方法として、対象駅をおおよそカバーする範囲の矩形ポリゴンを作成し、そのポリゴンと重なる駅を抽出する手順で進めていきます。
tokyo_bbox <- st_bbox(
c(xmin = 139.25, ymin = 35.6, xmax = 139.8, ymax = 35.8),
crs = st_crs(station)
)
station <- station |> st_filter(st_as_sfc(tokyo_bbox))
station |>
tm_shape(bbox = tokyo_bbox) +
tm_dots() +
tm_layout(text.fontfamily = "BIZ UDPGothic") +
tm_credits(ksj_gsi_credit) +
tm_basemap(gsi_tile)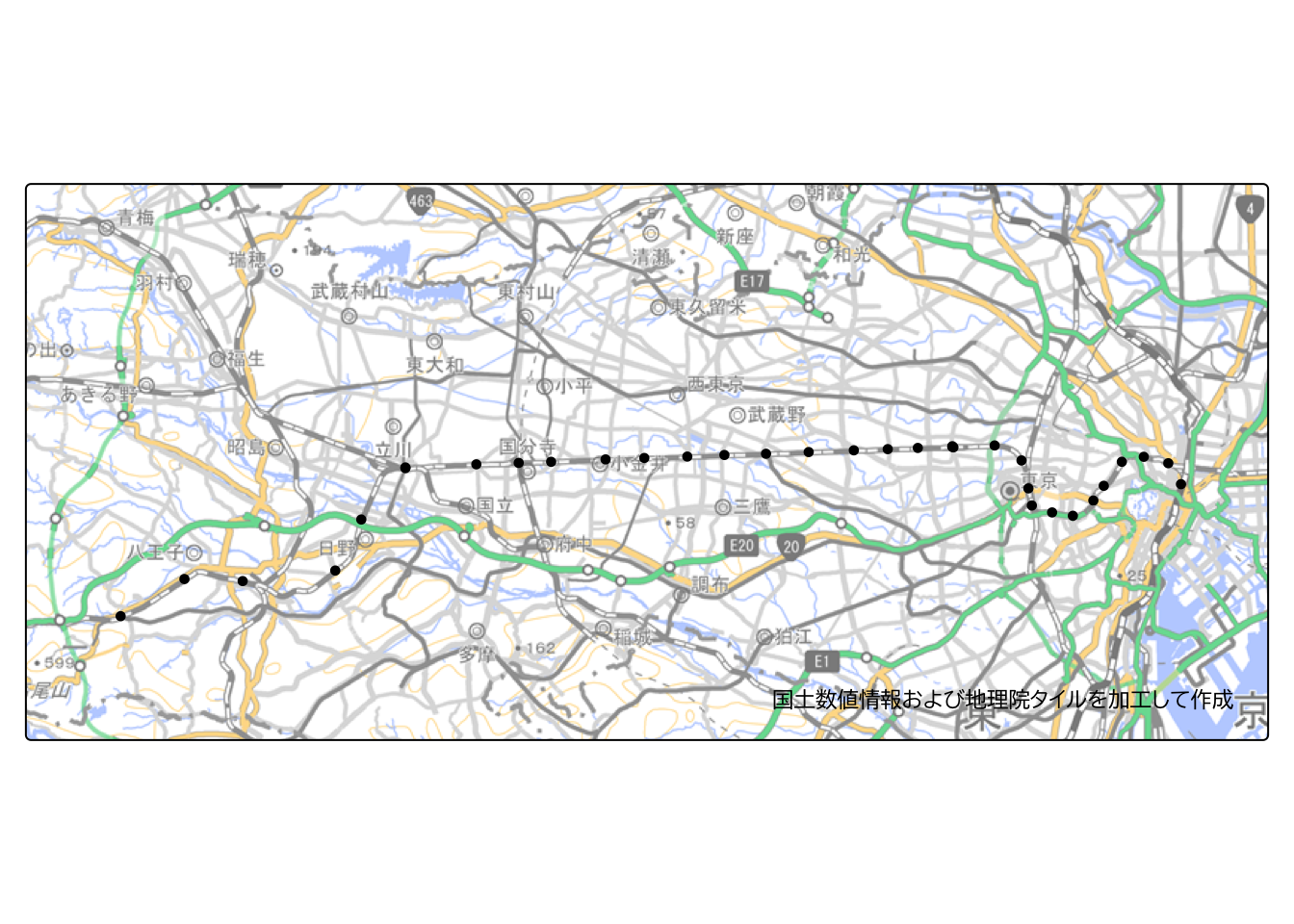
駅のポイントデータの作成
ここまでの手順で全国の駅データから、分析対象の東京都内の中央線の駅を抽出することができました。
次はこの駅データからポイントデータを作成します。 ここで特定の駅のデータを拡大して確認してみると、ひとつの駅が複数のラインデータで作成されていることが確認できます。
station |>
filter(N02_005 == "立川") |>
tm_shape(bbox = bb(URLencode("立川"), width = 0.02, height = 0.01)) +
tm_lines(col = "red") +
tm_layout(text.fontfamily = "BIZ UDPGothic") +
tm_credits(ksj_gsi_credit) +
tm_basemap(gsi_tile)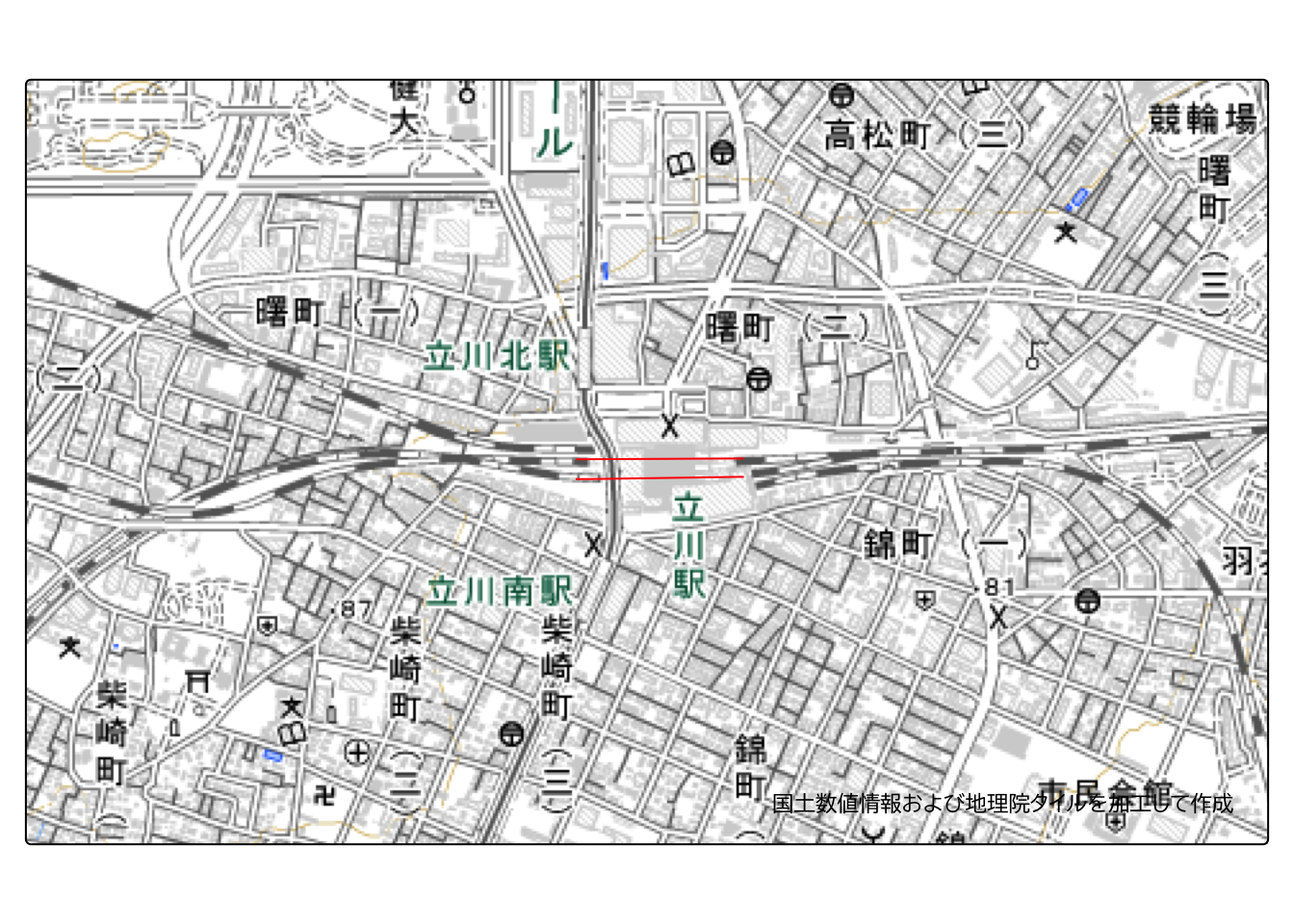
このままでは同じ駅名(N02_005)の地物が複数存在している状態であり、駅ごとの集計が難しいです。 そこで、同一駅名の地物を1つのライン(マルチライン)に統合し、その重心にポイントを作成することで、各駅を1つのポイントで表現できるようにします。 (sfオブジェクトに対してsummariseを実行すると、内部でst_union()が実行されます)
station <- station |>
group_by(N02_005) |> summarise() |> st_centroid()Warning: st_centroid assumes attributes are constant over geometries
ヒント
sfオブジェクトに対してsummariseを実行すると、内部でst_union()が実行され、地物が統合されます。
ラベルを表示してすべての駅を確認してみると、神田駅から高尾駅までのポイントレイヤが作成されていることがわかります。 下図では、出力結果がわかりやすいように、背景地図を非表示にしています。
station |> tm_shape(bbox = tokyo_bbox) +
tm_text("N02_005", size = 1/2, ymod = 1) +
tm_dots() +
tm_credits("国土数値情報を加工して作成")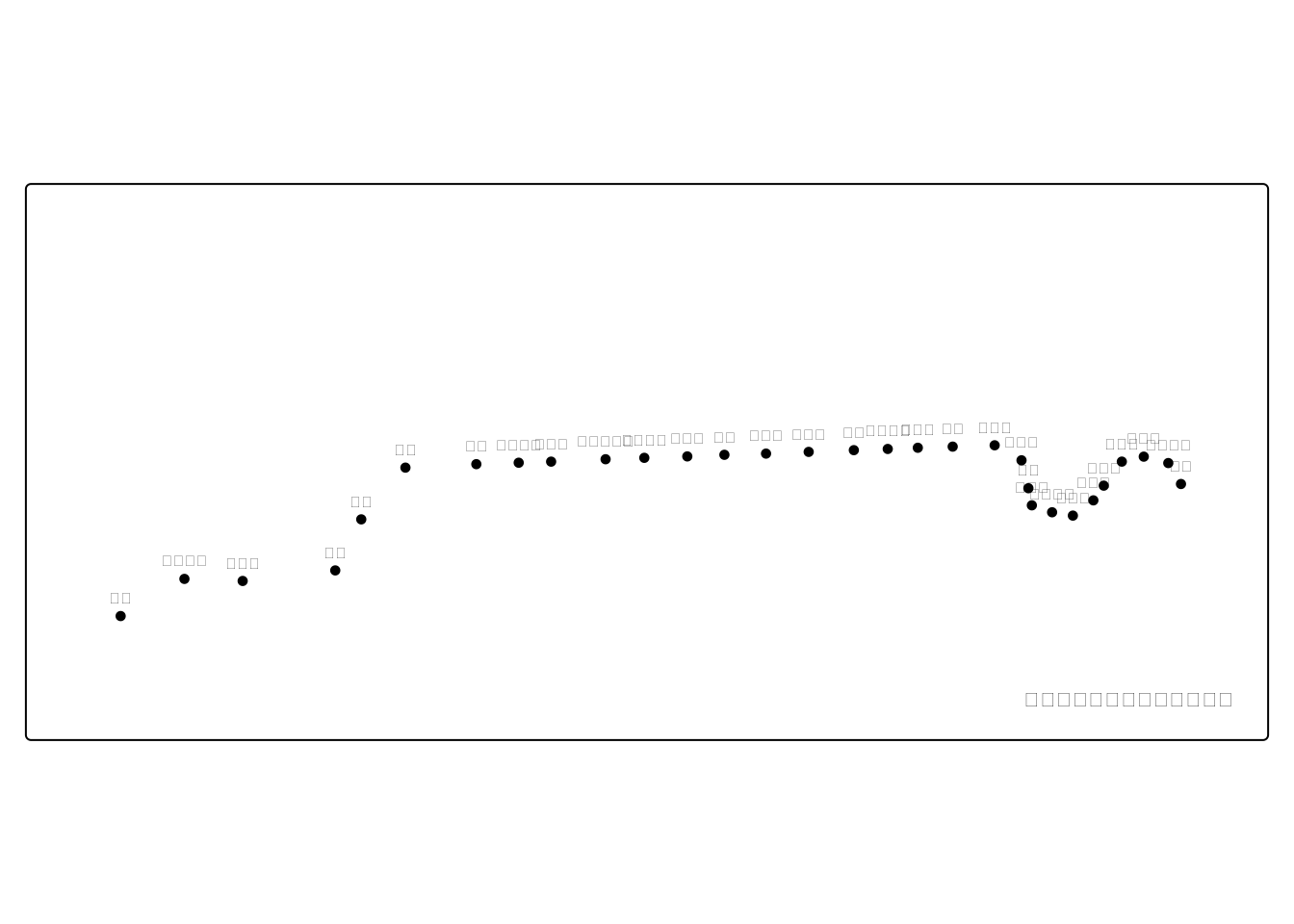
駅から500メートルのバッファの作成
次のステップでは、駅のポイントデータから500メートルのバッファ(円形の範囲)を作成し、これを地価公示の集計基準として使用します。
正確な距離のバッファを作成するためには、元のレイヤを平面直角座標系に変換する必要があるため、まずは投影変換を実施します。
land_price <- land_price |> st_transform(6677)
station <- station |> st_transform(6677)
tokyo_bbox <- tokyo_bbox |> st_transform(6677)ここでは東京都のデータを使用しているため、st_transform関数の引数に6677(平面直角座標系IX系[JGD2011]のEPSGコード)を与えています。 対象地点の平面直角座標系のゾーンを確認したい場合は、国土地理院のページを参照してください。
これでバッファを作成できる準備が整ったので、駅から500メートルのバッファを作成します。
buffer <- station |> st_buffer(500)下図のように、駅のポイントから500メートルのポリゴンデータを作成することができました。
buffer |>
tm_shape(bbox = tokyo_bbox) +
tm_polygons() +
tm_layout(text.fontfamily = "BIZ UDPGothic") +
tm_credits(ksj_gsi_credit) +
tm_basemap(gsi_tile)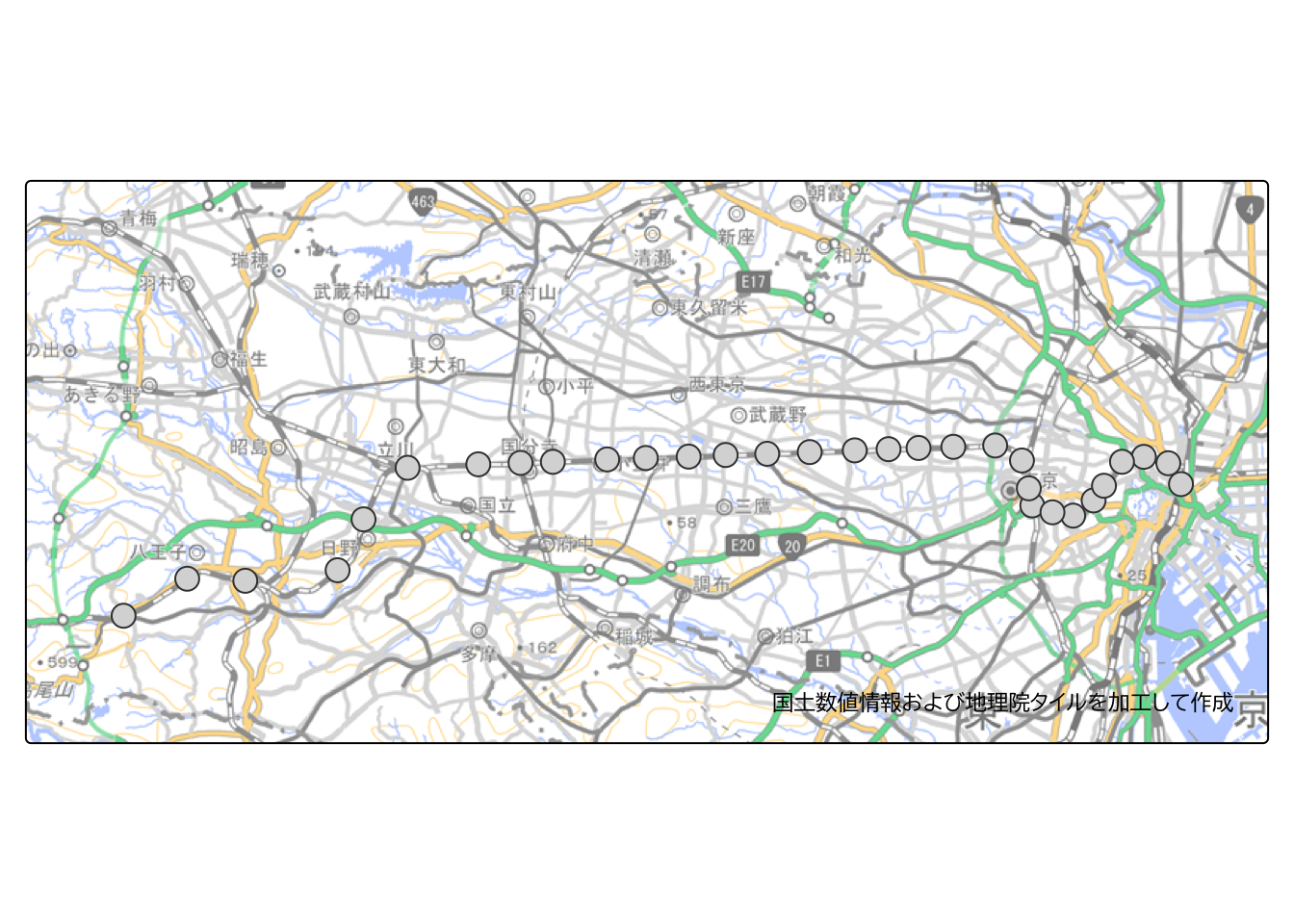
地価の集計
ここまでで準備が整ったので、集計の処理を実施してみます。 st_join関数で、地価のポイントデータにバッファのポリゴンデータを空間結合します。
buffer <- buffer |> st_join(land_price) |>
group_by(N02_005) |> summarise(med_price = median(L01_008))結果を確認してみます。 ここでは、Jenksの自然分類によって10段階に分類しています。
jenks <- tm_scale_intervals(n = 10, style = "jenks", values = "-matplotlib.spectral")
buffer |>
tm_shape(bbox = tokyo_bbox) +
tm_polygons(fill = "med_price", fill.scale = jenks) +
tm_layout(text.fontfamily = "BIZ UDPGothic") +
tm_credits(ksj_gsi_credit) +
tm_basemap(gsi_tile)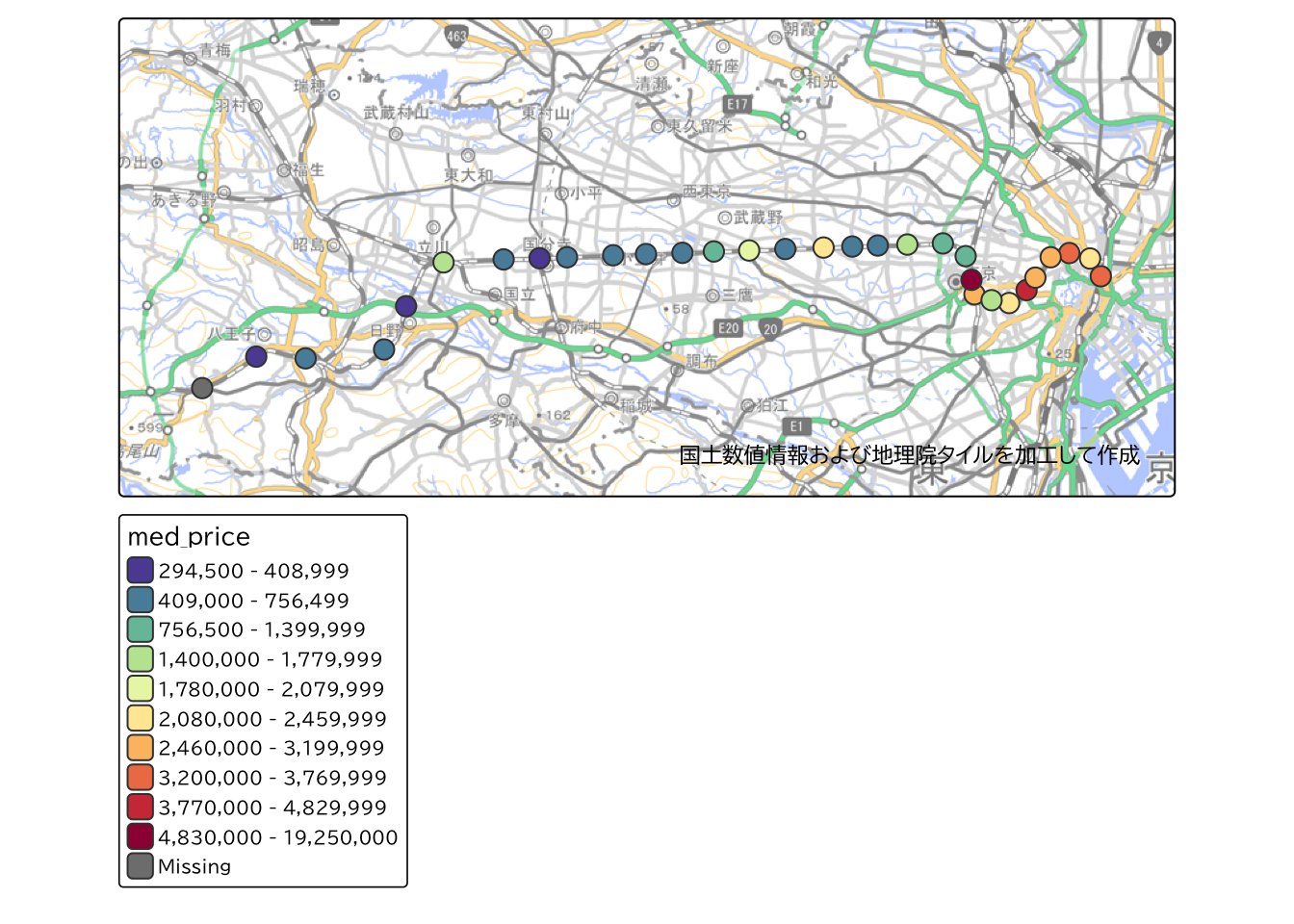
中央線のうち東側のエリアを中心に結果を確認してみます。
jenks <- tm_scale_intervals(n = 10, style = "jenks", values = "-matplotlib.spectral")
buffer |>
tm_shape(bbox = bb(URLencode("東中野"), width = 0.22, height = 0.11)) +
tm_polygons(fill = "med_price", fill.scale = jenks) +
tm_text("N02_005", size = 1/2) +
tm_layout(text.fontfamily = "BIZ UDPGothic") +
tm_credits(ksj_gsi_credit) +
tm_basemap(gsi_tile)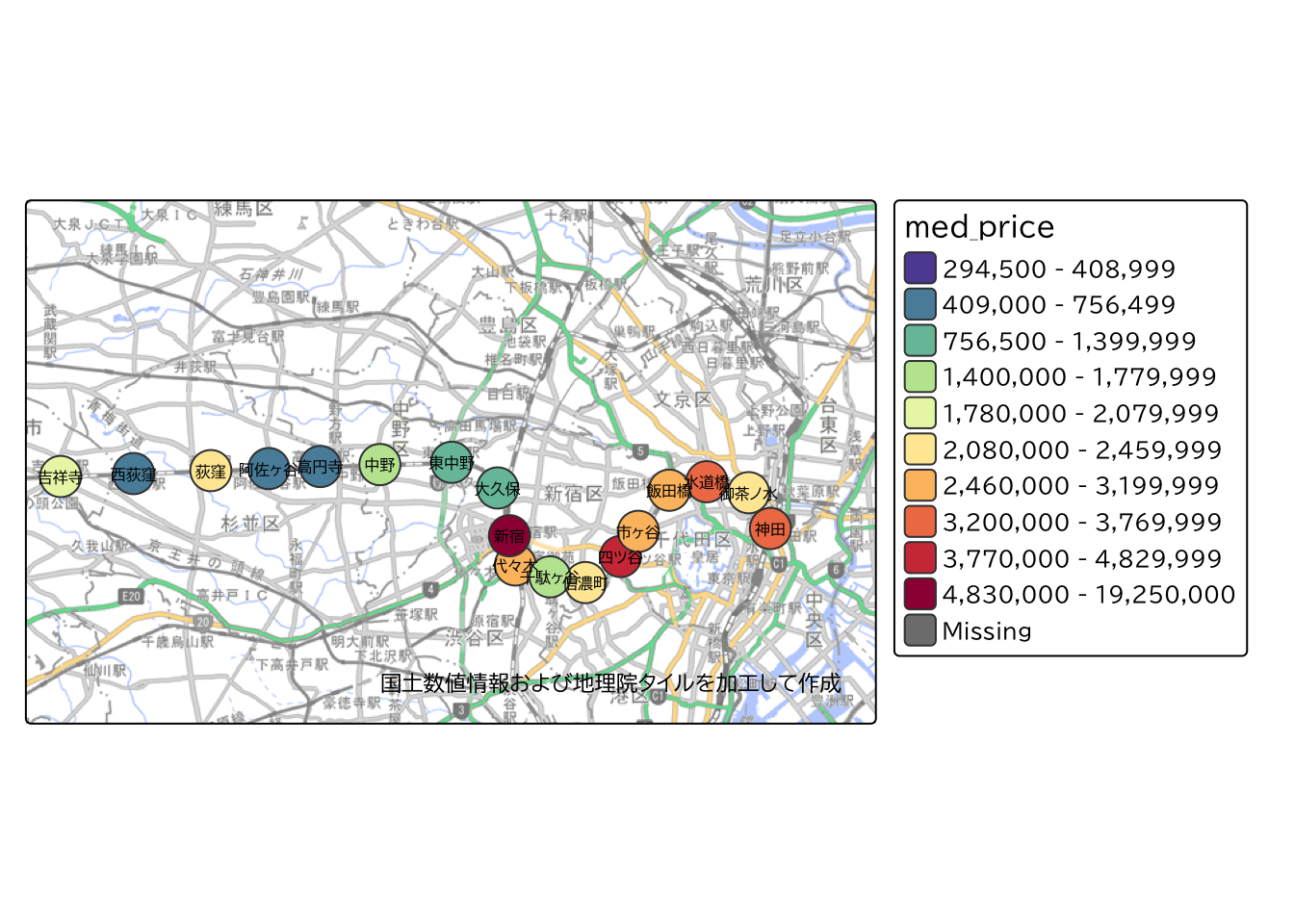
神田駅から新宿駅までのエリアは、西側エリアと比べて地価が高い傾向が見られます。大久保駅から西へ向かうにつれて地価は徐々に低くなりますが、荻窪駅や吉祥寺駅の周辺は、近隣の駅と比較しても地価が高くなっていることがわかります。
おわりに
本記事では、Rを使用した国土数値情報 地価公示データの分析手法を紹介しました。 変動率の可視化や駅勢圏での集計など、実務に即した分析方法を解説しています。 これらの手法は、地価公示以外の位置情報を持つデータにも応用できるため、様々な空間分析のヒントとして活用してみましょう。
ノート使用したパッケージについて
この記事の執筆に使用したパッケージとそのバージョンは以下の通りです。
A large number of files (1095 in total) have been discovered.
It may take renv a long time to scan these files for dependencies.
Consider using .renvignore to ignore irrelevant files.
See `?renv::dependencies` for more information.
Set `options(renv.config.dependencies.limit = Inf)` to disable this warning.| package | loadedversion | source |
|---|---|---|
| sf | 1.1-1 | CRAN (R 4.6.0) |
| tidyverse | 2.0.0 | CRAN (R 4.6.0) |
| tmap | 4.3 | CRAN (R 4.6.0) |
| tmaptools | 3.3 | CRAN (R 4.6.0) |
| units | 1.0-1 | CRAN (R 4.6.0) |